Contemporary options for are the non-saturating activation functions [Mur22, Sec. 13.4.3], although the term is not accurate.
Below, should be understood as the output of the summing junction.
The rectified linear unit (ReLU) [NH10] is the unipolar function:
ReLU is differentiable except at , but by definition, for .
ReLU has the advantage of having well-behaved derivatives, which are either 0 or 1.
This simplifies optimisation [ZLLS23, Sec. 5.1.2.1] and mitigates the infamous vanishing gradients problem associated with traditional activation functions.
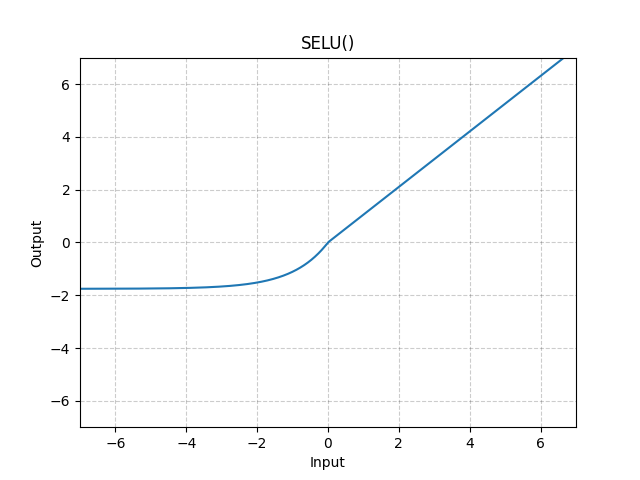
The scaled exponential linear unit or self-normalising ELU (SELU) [KUMH17] extends ELU:
where ensures a slope of larger than 1 for positive inputs; see Fig. 2.
SELU was invented for self-normalising neural networks (SNNs), which are meant to 1️⃣ be robust to perturbations, 2️⃣ not have high variance in their training errors.
SNNs push neuron activations to zero mean and unit variance, leading to the same effect as batch normalisation, which enables robust deep learning.
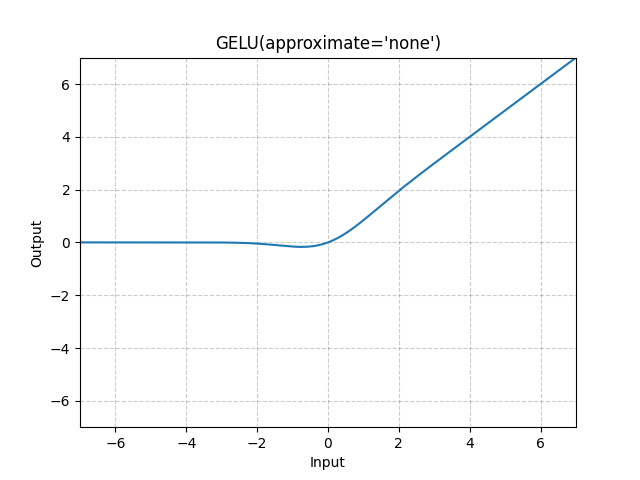
The Gaussian error linear unit (GELU) [HG20] extends ReLU and ELU:
where is the cumulative distribution function for the Gaussian distribution, and is the error function .
Unlike most other activation functions, GELU is not convex or monotonic; the increased curvature and non-monotonicity may allow GELUs to more easily approximate complicated functions than ReLUs or ELUs can.
ReLU gates the input depending upon its sign, whereas GELU weights its input depending upon how much greater it is than other inputs.
GELU is a popular choice for implementing transformers; see for example Hugging Face’s implementation of activation functions.
D.-A. Clevert, T. Unterthiner, and S. Hochreiter, Fast and accurate deep network learning by exponential linear units (ELUs), in ICLR, 2016. Available at https://arxiv.org/abs/1511.07289.
K. He, X. Zhang, S. Ren, and J. Sun, Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification, in 2015 IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1026–1034. https://doi.org/10.1109/ICCV.2015.123.
[HG20]
D. Hendrycks and K. Gimpel, Gaussian error linear units (GELUs), arXiv preprint arXiv:1606.08415, 2020, first appeared in 2016.
K. P. Murphy, Probabilistic Machine Learning: An introduction, MIT Press, 2022. Available at http://probml.ai.
[NH10]
V. Nair and G. E. Hinton, Rectified linear units improve restricted Boltzmann machines, in Proceedings of the 27th International Conference on International Conference on Machine Learning, ICML’10, Omnipress, Madison, WI, USA, 2010, p. 807–814.
[ZLLS23]
A. Zhang, Z. C. Lipton, M. Li, and A. J. Smola, Dive into Deep Learning, 2023, interactive online book, accessed 17 Feb 2023. Available at https://d2l.ai/.
Active learning
by Yee Wei Law - Wednesday, 25 October 2023, 9:39 AM
References
[]
.
Adversarial machine learning
by Yee Wei Law - Tuesday, 21 January 2025, 11:31 PM
AML is the study of 1️⃣ the capabilities of attackers and their goals, as well as the design of attack methods that exploit the vulnerabilities of ML during the ML life cycle; 2️⃣
the design of ML algorithms that can withstand these security and privacy challenges [OV24].
The impact of adversarial examples on deep learning is well known within the computer vision community, and documented in a body of literature that has been growing exponentially since Szegedy et al.’s discovery [SZS+14].
The field is moving so fast that the taxonomy, terminology and threat models are still being standardised.
L. Huang, A. D. Joseph, B. Nelson, B. I. Rubinstein, and J. D. Tygar, Adversarial machine learning, in Proceedings of the 4th ACM Workshop on Security and Artificial
Intelligence, AISec ’11, Association for Computing Machinery, New York, NY, USA, 2011, p. 43 – 58. https://doi.org/10.1145/2046684.2046692.
[OV24]
A. Oprea, A. Vassilev, A. Fordyce, and H. Anderson, Adversarial machine learning: A taxonomy and terminology of attacks and mitigations, NIST AI 100-2e2023 ipd, January 2024. https://doi.org/10.6028/NIST.AI.100-2e2023.
[SZS+14]
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, Intriguing properties of neural networks, in International Conference on Learning
Representations, 2014. Available at https://research.google/pubs/pub42503/.
Deep learning library Apache MXNet reached version 1.9.1 when it was retired in 2023.
Despite its obsolescence, there are MXNet-based projects that have not yet been ported to other libraries.
In the process of porting these projects, it is useful to be able to evaluate their performance in MXNet, and hence it is useful to be able to set up MXNet.
The problem is the dependencies of MXNet have not been updated for a while, and installation is not as straightforward as the installation guide makes it out to be. The installation guide here is applicable to Ubuntu 24.04 LTS on WSL2 and requires
NumPy version 1.23.5 (last version before 1.24, which is incompatible with MXNet),
cuDNN v8.9.7 (latest version applicable to CUDA 11.x, and the Ubuntu22.04 x86_64 variant works for Ubuntu 24.04),
NCCL 2.16.5 (latest version supporting CUDA 11.8).
After setting up all the above, do
pip install mxnet-cu112
Some warnings like this will appear but are inconsequential:
cuDNN lib mismatch: linked-against version 8907 != compiled-against version 8101. Set MXNET_CUDNN_LIB_CHECKING=0 to quiet this warning.
by Yee Wei Law - Sunday, 19 January 2025, 10:54 AM
An autoencoder
References
[Mur22]
K. P. Murphy, Probabilistic Machine Learning: An Introduction, MIT Press, 2022. Available at http://probml.ai.
[ZLLS23]
A. Zhang, Z. C. Lipton, M. Li, and A. J. Smola, Dive into Deep Learning, 2023, interactive online book, accessed 17 Feb 2023. Available at https://d2l.ai/.


 = \text{ReLU}(x) \triangleq \max(0,x) = \begin{cases}
x & \text{if }x>0, \\
0 & \text{otherwise.}
\end{cases}")

=0")

 = \text{LReLU}(x) \triangleq \max(ax,x) = \begin{cases}
x & \text{if }x>0, \\
ax & \text{otherwise,}
\end{cases}")


=a>0")
 = \text{PReLU}(x) \triangleq \max(ax,x) = \begin{cases}
x & \text{if }x>0, \\
ax & \text{otherwise,}
\end{cases}")
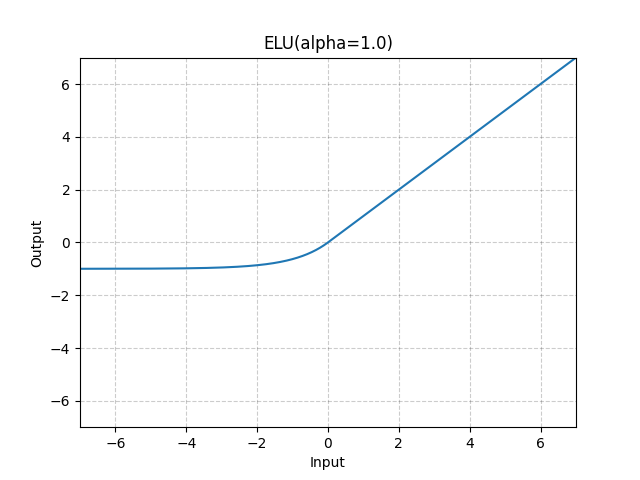
 = \text{ELU}(x) \triangleq \begin{cases}
x & \text{if }x>0, \\
\alpha(e^x-1) & \text{otherwise,}
\end{cases}")


 = \text{SELU}(x) \triangleq \lambda\text{ELU}(x),")

![\varphi(x) = \text{GELU}(x) \triangleq x\Phi(x) = \dfrac{x}{2}\left[1+\text{erf}(x/\sqrt{2})\right],](https://lo.unisa.edu.au/filter/tex/pix.php/2b58eace246ae23c0e4a88f1f8c72a50.gif "\varphi(x) = \text{GELU}(x) \triangleq x\Phi(x) = \dfrac{x}{2}\left[1+\text{erf}(x/\sqrt{2})\right],")
")

=(2/\sqrt{\pi})\int_0^xe^{-t^2}dt")