Special | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | ALL
2 |
|---|
2022 cyber threat trends | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Every year, major cybersecurity firms release their report on the trends of cyber threats/attacks they observe during that year. Some also release their forecast of cybersecurity trends for the next year. Examples of reports for 2022 are provided in the list of references. A summary of the trends observed in these reports is provided here, with additional commentary on how some of these attacks happened. Among the most impactful trends identified [Che22, Cro22b, Man22a, Spl22] are (in no particular order):
References
| ||||||||||||||||



A |
|---|
Abstract interpretation | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
High-level overviewAbstract interpretation, first formalised by Cousot and Cousot in 1977 [CC77], executes a program on an abstract machine to determine the properties of interest [vJ11, p. 1255]. The level of detail in the abstract machine specification typically determines the accuracy of the results. At one end of the spectrum is an abstract machine that faithfully represents the concrete semantics of the language. Abstract interpretation on such a machine 👆 would correspond to a concrete execution on the real machine. Typical abstract interpretation analyses, however, do not require detailed semantics. A bit of theoryFundamentally, the correctness problem of a program is undecidable, so approximation is necessary [Cou01, Abstract]. The purpose of abstract interpretation is to formalise this idea 👆 of approximation; see Fig. 1. Formally, abstract interpretation is founded in the theory for approximating sets and set operations [Cou01, Sec. 2]. The semantics of a program can be defined as the solution to a fixpoint (short for fixed point) equation. Thus, an essential role of abstract interpretation is providing constructive and effective methods for fixpoint approximation and checking by abstraction. By observing computations at different levels of abstraction (trace semantics → relational semantics → denotational semantics → weakest precondition semantics → Hoare logics), fixpoints can be approximated. Fig. 1: In abstract interpretation, the program analyzer computes an approximate semantics of the program [Cou01, Fig. 12]. The generator generates equations/constraints, the solution to which is a computer representation of the program semantics.The solver solves these equations/constraints. The diagnoser checks the solutions with respect to the specification and outputs “yes”, “no” or “unknown”.  References
| ||||||||||
Address space layout randomisation (ASLR) | ||||
|---|---|---|---|---|
Address space layout randomisation (ASLR) refers to the randomisation of the locations of the key components of an executable — stack, heap, libraries and memory-mapped files, executable code — in the address space; to mitigate remote code execution and other attacks targeting CWE-787 and CWE-125. Watch Dr. Yeongjin Jang’s lecture on ASLR: ASLR targets memory corruption vulnerabilities such as buffer overflows, which typically occur when data get written to memory that is smaller than the size of the data — a common programming error when using a memory-unsafe language like C. By introducing uncertainty into the locations of the shellcode (or any other attack code), ASLR hinders exploitations of memory corruption vulnerabilities. There are many ways ASLR can be done, and different operating systems do it differently. There are three dimensions to be considered [MGRR19]: When This is about when the entropy used for ASLR is generated (see Table 1):
What This is about what to randomise. In the extreme, if a single object (e.g., the executable) is not randomised, ASLR is considered to be broken. An “aggressive” form of ASLR is when the randomisation is applied to the logical elements contained in the memory objects: processor instructions, blocks of code, functions, and even the data structures of the application; see Table 1. In this case 👆, the compiler, linker and loader are required to play an active role. This form of ASLR is not known to be in use. How Table 1 lists the main strategies:
References
| ||||

Advanced persistent threat (APT) | ||||
|---|---|---|---|---|
Advanced persistent threat (APT, see Definition 1) has been occupying the attention of many cybersecurity firms. Definition 1: Advanced persistent threat (APT) [NIS11, Appendix B]
An adversary that possesses sophisticated levels of expertise and significant resources which allow it to create opportunities to achieve its objectives using multiple attack vectors (e.g., cyber, physical, and deception). These objectives typically include establishing and extending footholds within the information technology infrastructure of the targeted organisations for purposes of exfiltrating information, undermining or impeding critical aspects of a mission, program, or organization; or positioning itself to carry out these objectives in the future. The advanced persistent threat: 1️⃣ pursues its objectives repeatedly over an extended period of time; 2️⃣ adapts to defenders’ efforts to resist it; and 3️⃣ is determined to maintain the level of interaction needed to execute its objectives. Since APT groups are characterised by sophistication, persistence and resourcefulness, they are challenging to counter. Lists of APT groups are being actively maintained, e.g., by MITRE and Mandiant. References
| ||||
Application security testing | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Application security testing can be static or dynamic. Static application security testing (SAST) is a specialisation of static (code/program) analysis. Watch an introduction to static code analysis on LinkedIn Learning: Static analysis from Developing Secure Software by Jungwoo Ryoo Exploring tools for static analysis from Developing Secure Software by Jungwoo Ryoo Definitions and history:
Challenges:
Tools:
Dynamic application security testing (DAST) is a specialisation of dynamic (code/program) analysis. Watch an introduction to dynamic code analysis on LinkedIn Learning: Dynamic analysis from Developing Secure Software by Jungwoo Ryoo Dynamic analysis tools from Developing Secure Software by Jungwoo Ryoo Definitions and history:
Challenges:
Tools: References
| ||||||||||||||||||||||||||||


Asymmetric-key cryptography | ||
|---|---|---|
Asymptotic notation | ||
|---|---|---|
See complexity theory. | ||
Authenticated encryption with associated data (AEAD) | |||
|---|---|---|---|
See 👇 attachment (coming soon) or the latest source on Overleaf. | |||
B |
|---|
Block ciphers and their modes of operation | |||
|---|---|---|---|
See 👇 attachment for block ciphers and their modes of operation.
| |||
Bundle Protocol | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
The original purpose of the delay-tolerant networking (DTN) protocols was to provide space communications scenarios with network-layer functionality similar to that provided by IP-based networks on Earth. Since space communication scenarios cannot be supported by the terrestrial IP protocol suite, a new solution had to be developed. The CCSDS Bundle Protocol (BP), based on Bundle Protocol version 6 as defined in RFC 5050 [SB07] and RFC 6260 [Bur11], is meant to provide 1️⃣ basic network-layer functionality, and 2️⃣ storage capability to enable networking benefits even in the presence of delays, disconnections, and rate mismatches [IEH+19].
More concretely, the BP provides network-layer services to applications through these capabilities [CCS15, Secs. 1.1 and 2.1]:
When used in conjunction with the Bundle Security Protocol, as defined in RFC 6257 [FWSL11], the BP also provides:
 The BP is such an important protocol several open-source implementations exist:
References
| ||||||||||||||||||||||||||||
C |
|---|
CCSDS File Delivery Protocol | ||||||||
|---|---|---|---|---|---|---|---|---|
The CCSDS File Delivery Protocol (CFDP) is standardised in
CFDP has existed for decades, and it is intended to enable packet delivery services in space (space-to-ground, ground-to-space, and space-to-space) environments [CCS20, Sec. 1.1]. CFDP defines 1️⃣ a protocol suitable for the transmission of files to and from spacecraft data storage, and 2️⃣ file management services to allow control over the storage medium [CCS20, Sec. 2.1]. CFDP assumes a virtual filestore and associated services that an implementation must map to the capabilities of the actual underlying filestore used [CCS20, Sec. 1.1]. File transfers can be either unrealiable (class 1) or reliable (class 2): Class 1 [CCS20, Sec. 7.2] All file segments are transferred without the possibility of retransmission. End of file (EOF) is not acknowledged by the receiver. When the flag Closure Requested is set, the receiver is required to send a Finished PDU upon receiving all file segments (or when the request is cancelled), but the sender does not need to acknowledge the Finished PDU. The Closure Requested flag is useful when the underlying communication protocol is reliable. Class 2 [CCS20, Sec. 7.3] The receiver is required to acknowledge the EOF PDU and the sender has to acknowledge the Finished PDU. Sending a PDU that requires acknowledgment triggers a timer. When the timer expires and if the acknowledgment has not been received, the relevant file segment PDU is resent. This repeats until the ACK Timer Expiration Counter [CCS21b, Sec. 4.4] reaches a predefined maximum value. Finally, if the counter has reached its maximum value and the acknowledgment has still not been received, a fault condition is triggered which may cause the transfer to be abandoned, canceled or suspended. The receiver can also indicate missing metadata or data by sending NAK PDUs. Fig. 2 shows a sample class-2 Copy File transaction between two entities.  Fig. 3 summarises 1️⃣the operation primitives and PDUs in CFDP, as well as 2️⃣ the relationships of these primitives and PDUs to the operational process from initiation through termination.  Watch an introduction to the CFDP on YouTube: There are several open-source implementations of CFDP, e.g.,
References
| ||||||||
CCSDS optical communications physical layer | |||
|---|---|---|---|
CCSDS publications naming convention | |||
|---|---|---|---|
Publications from the Consultative Committee for Space Data Systems (CCSDS) can be found here. Each publication has an identifier of the form MMM.MM-A-N, where
| |||
CCSDS RF communications physical layer | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
The International Telecommunication Union (ITU) has defined a series of regulations or recommendations for space research, space operations and Earth exploration-satellite services [ITU20, Recommendation ITU-R SA.1154-0], but CCSDS has tweaked these recommendations for their purposes [CCS21, Sec. 1.5]. CCSDS has defined two mission categories [CCS21, Sec. 1.5]:
Orthogonal to the preceding classification, CCSDS has also divided their recommendations into these six categories [CCS21, Sec. 2]:
For example, the recommendations for telemetry RF comm are summarised in Table 1. Note:
The Proximity-1 physical layer is separate from all the above. References
| ||||||||||

Complexity theory | |||
|---|---|---|---|
The attachment covers the following topics:
| |||
Cryptography: introductory overview | |||
|---|---|---|---|
See 👇 attachment or the latest source on Overleaf.
| |||
CWE-1037 | ||||
|---|---|---|---|---|
This is a student-friendly explanation of the hardware weakness CWE-1037 “Processor Optimization Removal or Modification of Security-critical Code”, which is susceptible to
While increasingly many security mechanisms have been baked into software, the processors themselves are optimising the execution of the programs such that these mechanisms become ineffective. Example 1
🛡 General mitigation
Software fixes exist but are partial as the use of speculative execution remains a favourable way of increasing processor performance. Fortunately, the likelihood of successful exploitation is considered to be low. References
| ||||
CWE-1189 | |||
|---|---|---|---|
This is a student-friendly explanation of the hardware weakness CWE-1189 “Improper Isolation of Shared Resources on System-on-a-Chip (SoC)”, which is susceptible to
A system-on-a-chip (SoC) may have many functions but a limited number of pins or pads. A pin can only perform one function at a time, but it can be configured to perform multiple functions; this technique is called pin multiplexing. Similarly, multiple resources on the chip may be shared to multiplex and support different features or functions. When such resources are shared between trusted and untrusted agents, untrusted agents may be able to access assets authorised only for trusted agents. Consider the generic SoC architecture in Fig. 1 below: 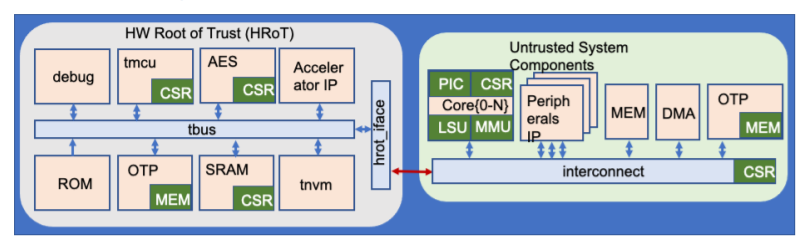 The SRAM in the hardware root of trust (HRoT) is mapped to the core{0-N} address space accessible by the untrusted part of the system. The HRoT interface (hrot_iface in Fig. 1) mediates access to private memory ranges, allowing the SRAM to function as a mailbox for communication between the trusted and untrusted partitions.
Example 1
An example of CWE-1189 in the real world is CVE-2020-8698 with the description: “Improper isolation of shared resources in some Intel(R) Processors may allow an authenticated user to potentially enable information disclosure via local access”.
🛡 General mitigation
Untrusted agents should not share resources with trusted agents, so when sharing resources, avoid mixing agents of varying trust levels. | |||
CWE-1191 | ||||
|---|---|---|---|---|
This is a student-friendly explanation of the hardware weakness CWE-1191 “On-Chip Debug and Test Interface With Improper Access Control”, which is susceptible to
The internal information of a device may be accessed through a scan chain of interconnected internal registers, typically through a Joint Test Action Group (JTAG) interface.
The JTAG interface is so important in the area of hardware security that you should make sure you read the knowledge base entry carefully. Sometimes, designers choose not to expose the debug pins on the motherboard.
Example 1
Barco’s ClickShare family of products is designed to provide end users with wireless presenting capabilities, eliminating the need for wired connections such as HDMI [Wit19]. ClickShare Button R9861500D01 devices, before firmware version 1.9.0, were vulnerable to CVE-2019-18827.
🛡 General mitigation
Disable the JTAG interface or implement access control (at least debug authorisation). Authentication logic, if implemented, should resist timing attacks. Security-sensitive data stored in registers, such as keys, should be cleared when entering debug mode. References
| ||||

CWE-125 | ||
|---|---|---|
This is a student-friendly explanation of the software weakness CWE-125 “Out-of-bounds Read”, where the vulnerable entity reads data past the end, or before the beginning, of the intended buffer. This weakness is susceptible to
This and CWE-787 are two sides of the same coin. Typically, this weakness allows an attacker to read sensitive information from unexpected memory locations or cause a crash. Example 1
A high-profile vulnerability is CVE-2014-0160, infamously known as the Heartbleed bug. Watch an accessible explanation given by Computerphile: 🛡 General mitigation
| ||
CWE-1256 | ||
|---|---|---|
CWE-1260 | ||
|---|---|---|
This is a student-friendly explanation of the hardware weakness CWE-1260. Not ready for 2023. | ||
CWE-1300 | ||||
|---|---|---|---|---|
This is a student-friendly explanation of the hardware weakness CWE-1300 “Improper Protection of Physical Side Channels”, which is susceptible to A hardware product with this weakness does not contain sufficient protection mechanisms to prevent physical side channels from exposing sensitive information due to patterns in physically observable phenomena such as variations in power consumption, electromagnetic emissions (EME), or acoustic emissions. Example 1
Google’s Titan Security Key is a FIDO universal 2nd-factor (U2F) hardware device that became available since July 2018. Unfortunately, the security key is susceptible to side-channel attacks observing the local electromagnetic radiations of its secure element — an NXP A700x chip which is now discontinued — during an ECDSA signing operation [RLMI21]. The side-channel attack can clone the secret key in a Titan Security Key. Watch the USENIX Security ’21 presentation on the side-channel attack: More examples of side-channel attacks are available here. 🛡 General mitigation
The standard countermeasures are those that apply to CWE-1300 “Improper Protection of Physical Side Channels” and its parent weakness CWE-203 “Observable Discrepancy”. CWE-1300:
CWE-203:
References
| ||||
CWE-1384 | ||||
|---|---|---|---|---|
This is a student-friendly explanation of the hardware weakness CWE-1384 “Improper Handling of Physical or Environmental Conditions”, where a hardware product does not properly handle unexpected physical or environmental conditions that occur naturally or are artificially induced. This weakness CWE-1384 and the weakness CWE-1300 can be seen as two sides of a coin: while the latter is about leakage of sensitive information, the former is about injection of malicious signals. Example 1
The GhostTouch attack [WMY+22] generates electromagnetic interference (EMI) signals on the scan-driving-based capacitive touchscreen of a smartphone, which result in “ghostly” touches on the touchscreen; see Fig. 1. The EMI signals can be generated, for example, using ChipSHOUTER.  These ghostly touches enable the attacker to actuate unauthorised taps and swipes on the victim’s touchscreen. Watch the authors’ presentation at USENIX Security ’22: PCspooF is another example of an attack exploiting weakness CWE-1384. 🛡 General mitigation
Product specification should include expectations for how the product will perform when it exceeds physical and environmental boundary conditions, e.g., by shutting down. Where possible, include independent components that can detect excess environmental conditions and are capable of shutting down the product. Where possible, use shielding or other materials that can increase the adversary’s workload and reduce the likelihood of being able to successfully trigger a security-related failure. References
| ||||
CWE-787 | |||
|---|---|---|---|
This is a student-friendly explanation of the software weakness CWE-787 “Out-of-bounds write”, where the vulnerable entity writes data past the end, or before the beginning, of the intended buffer. This and CWE-125 are two sides of the same coin. This can be caused by incorrect pointer arithmetic (see Example 1), accessing invalid pointers due to incomplete initialisation or memory release (see Example 2), etc. Example 1
In the adjacent C code, char pointer Reminder: In a POSIX environment, a C program can be compiled and linked into an executable using command Example 2
In the adjacent C code, after the memory allocated to Typically, the weakness CWE-787 can result in corruption of data, a crash, or code execution. 🛡 General mitigation
A long list of mitigation measures exist, so only a few are mentioned here:
Read about more measures here. Example 3
Using the 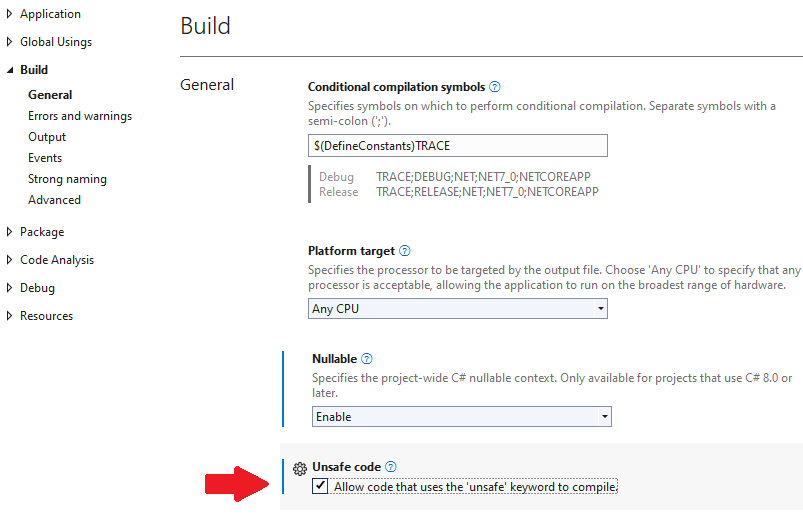 Enabling compilation of unsafe code in Visual Studio as per Fig. 1, the code above can be compiled. Once compiled and run, the code above will not trigger any runtime error, unless the line writing Question: What runtime error would the | |||
CWE-79 | ||||
|---|---|---|---|---|
This is a student-friendly explanation of the software weakness CWE-79 “Improper Neutralization of Input During Web Page Generation ('Cross-site Scripting')”, which is susceptible to
This weakness exists when user-controllable input is not neutralised or is incorrectly neutralised before it is placed in output that is used as a web page that is served to other users. In general, cross-site scripting (XSS) vulnerabilities occur when:
Once the malicious script is injected, a variety of attacks are achievable, e.g.,
The attacks above can usually be launched without alerting the victim. Even with careful users, URL encoding or Unicode can be used to obfuscate web requests, to make the requests look less suspicious. Watch an introduction to XSS on LinkedIn Learning: Understanding cross-site scripting from Security Testing: Vulnerability Management with Nessus by Mike Chapple Watch a demonstration of XSS on LinkedIn Learning: Cross-site scripting attacks from Web Security: Same-Origin Policies by Sasha Vodnik Example 1
The vulnerability CVE-2022-20916 caused the web-based management interface of Cisco IoT Control Center to allow an unauthenticated, remote attacker to conduct an XSS attack against a user of the interface. The vulnerability was due to absence of proper validation of user-supplied input. 🛡 General mitigation
A long list of mitigation measures exist, so only a few are mentioned here:
Read about more measures here and also consult the OWASP Cross Site Scripting Prevention Cheat Sheet. References
| ||||
CWE-917 | ||||
|---|---|---|---|---|
This is a student-friendly explanation of the software weakness CWE-917 “Improper Neutralization of Special Elements used in an Expression Language Statement ('Expression Language Injection')”. The vulnerable entity constructs all or part of an expression language (EL) statement in a framework such as Jakarta Server Pages (JSP, formerly JavaServer Pages) using externally-influenced input from an upstream component, but it does not neutralise or it incorrectly neutralises special elements that could modify the intended EL statement before it is executed.
Example 1
The infamous vulnerability Log4Shell (CVE-2021-44228) that occupied headlines for months in 2022 cannot be a better example. Watch an explanation of Log4Shell on YouTube: 🛡 General mitigation
Avoid adding user-controlled data into an expression interpreter. If user-controlled data must be added to an expression interpreter, one or more of the following should be performed:
By default, disable the processing of EL expressions. In JSP, set the attribute References
| ||||
Cyber Kill Chain | ||||
|---|---|---|---|---|
The Cyber Kill Chain® framework/model was developed by Lockheed Martin as part of their Intelligence Driven Defense® model for identification and prevention of cyber intrusions. The model identifies what an adversary must complete in order to achieve its objectives. The seven steps of the Cyber Kill Chain sheds light on an adversary’s tactics, techniques and procedures (TTP): Watch a quick overview of the Cyber Kill Chain on LinkedIn Learning: Overview of the cyber kill chain from Ethical Hacking with JavaScript by Emmanuel Henri Example 1: Modelling Stuxnet with the Cyber Kill Chain
Stuxnet (W32.Stuxnet in Symantec’s naming scheme) was discovered in 2010, with some components being used as early as November 2008 [FMC11]. Stuxnet is a large and complex piece of malware that targets industrial control systems, leveraging multiple zero-day exploits, an advanced Windows rootkit, complex process injection and hooking code, network infection routines, peer-to-peer updates, and a command and control interface [FMC11]. Watch a brief discussion of modelling Stuxnet with the Cyber Kill Chain: Stuxnet and the kill chain from Practical Cybersecurity for IT Professionals by Malcolm Shore ⚠ Contrary to what the video above claims, Stuxnet does have a command and control routine/interface [FMC11]. References
| ||||

D |
|---|
Data flow analysis | ||||||
|---|---|---|---|---|---|---|
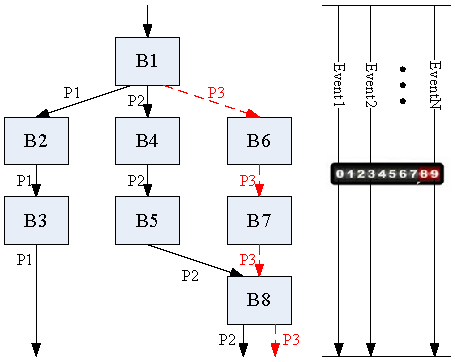
This continues from discussion of application security testing. Data flow analysis is a static analysis technique for calculating facts of interest at each program point, based on the control flow graph representation of the program [vJ11, p. 1254]. A canonical data flow analysis is reaching definitions analysis [NNH99, Sec. 2.1.2]. For example, if statement is Reaching definitions analysis determines for each statement that uses variable Example 1 [vJ11, pp. 1254-1255]
In the example below, the definition
x at line 1 reaches line 2, but does not reach beyond line 3 because x is assigned on line 3.
More formally, data flow analysis can be expressed in terms of lattice theory, where facts about a program are modelled as vertices in a lattice. The lattice meet operator determines how two sets of facts are combined. Given an analysis where the lattice meet operator is well-defined and the lattice is of finite height, a data flow analysis is guaranteed to terminate and converge to an answer for each statement in the program using a simple iterative algorithm. A typical application of data flow analysis to security is to determine whether a particular program variable is derived from user input (tainted) or not (untainted). Given an initial set of variables initialised by user input, data flow analysis can determine (typically an over approximation of) all variables in the program that are derived from user data. References
| ||||||


Delay-tolerant networking (DTN) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
In a mobile ad hoc network (MANET, see Definition 1), nodes move around causing connections to form and break over time. Definition 1: Mobile ad hoc network [PBB+17]
A wireless network that allows easy connection establishment between mobile wireless client devices in the same physical area without the use of an infrastructure device, such as an access point or a base station. Due to mobility, a node can sometimes find itself devoid of network neighbours. In this case, the node 1️⃣ stores the messages en route to their destination (which is not the node itself), and 2️⃣ when it finds a route of the destination of the messages, forwards the messages to the next node on the route. This networking paradigm is called store-and-forward. A delay-tolerant networking (DTN) architecture [CBH+07] is a store-and-forward communications architecture in which source nodes send DTN bundles through a network to destination nodes. In a DTN architecture, nodes use the Bundle Protocol (BP) to deliver data across multiple links to the destination nodes. Watch short animation from NASA: Watch detailed lecture from NASA: References
| ||||||||||||
Differential power analysis | ||||
|---|---|---|---|---|
Kocher et al. [KJJ99] pioneered the method of differential power analysis (DPA). A power trace is a set of power consumption measurements taken over a cryptographic operation; see Fig. 1 for an example. 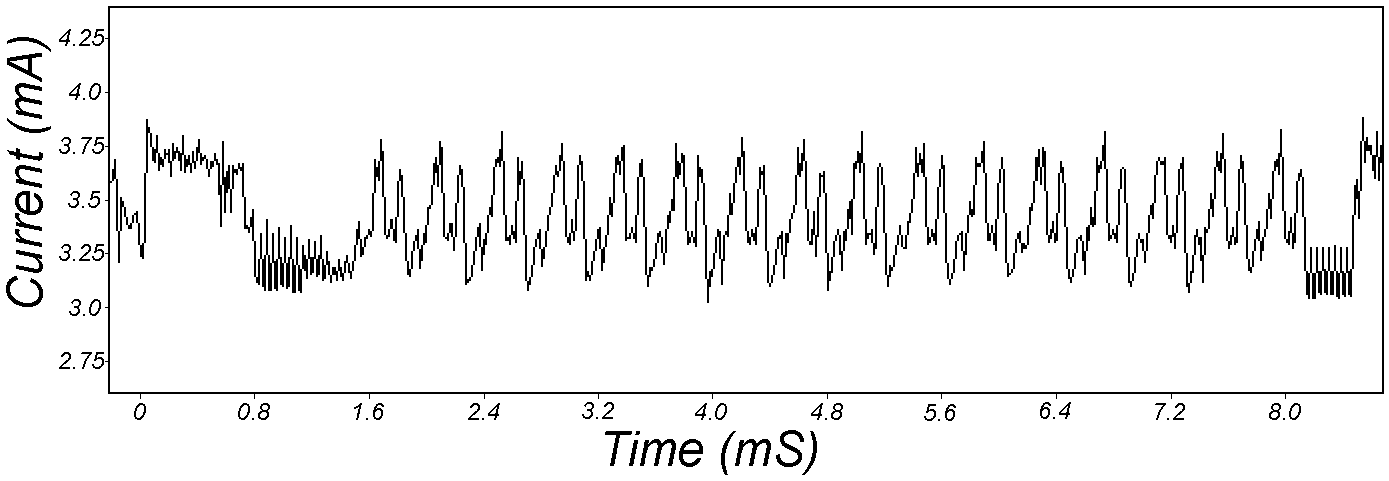 Let us define simple power analysis (SPA) before we get into DPA. SPA is the interpretation of direct power consumption measurements of cryptographic operations like Fig. 1. Watch a demonstration of SPA: Most hard-wired hardware implementations of symmetric cryptographic algorithms have sufficiently small power consumption variations that SPA cannot reveal any key bit. Unlike SPA, DPA is the interpretation of the difference between two sets of power traces. More precisely, this difference is defined as
where
Note each trace is associated with a different ciphertext.  Fig. 3: The Feistel function of DES, where E denotes the expansion permutation that expands a 32-bit input to 48 bits. During decryption of , denotes the half block (32 bits). If bit enters S-box S1, then is the 6-bit subkey that enters S-box S1.  ⚠ DPA was originally devised for DES but it can be adapted to other cryptographic algorithms. DPA uses power consumption measurements to determine whether a key block guess is correct.
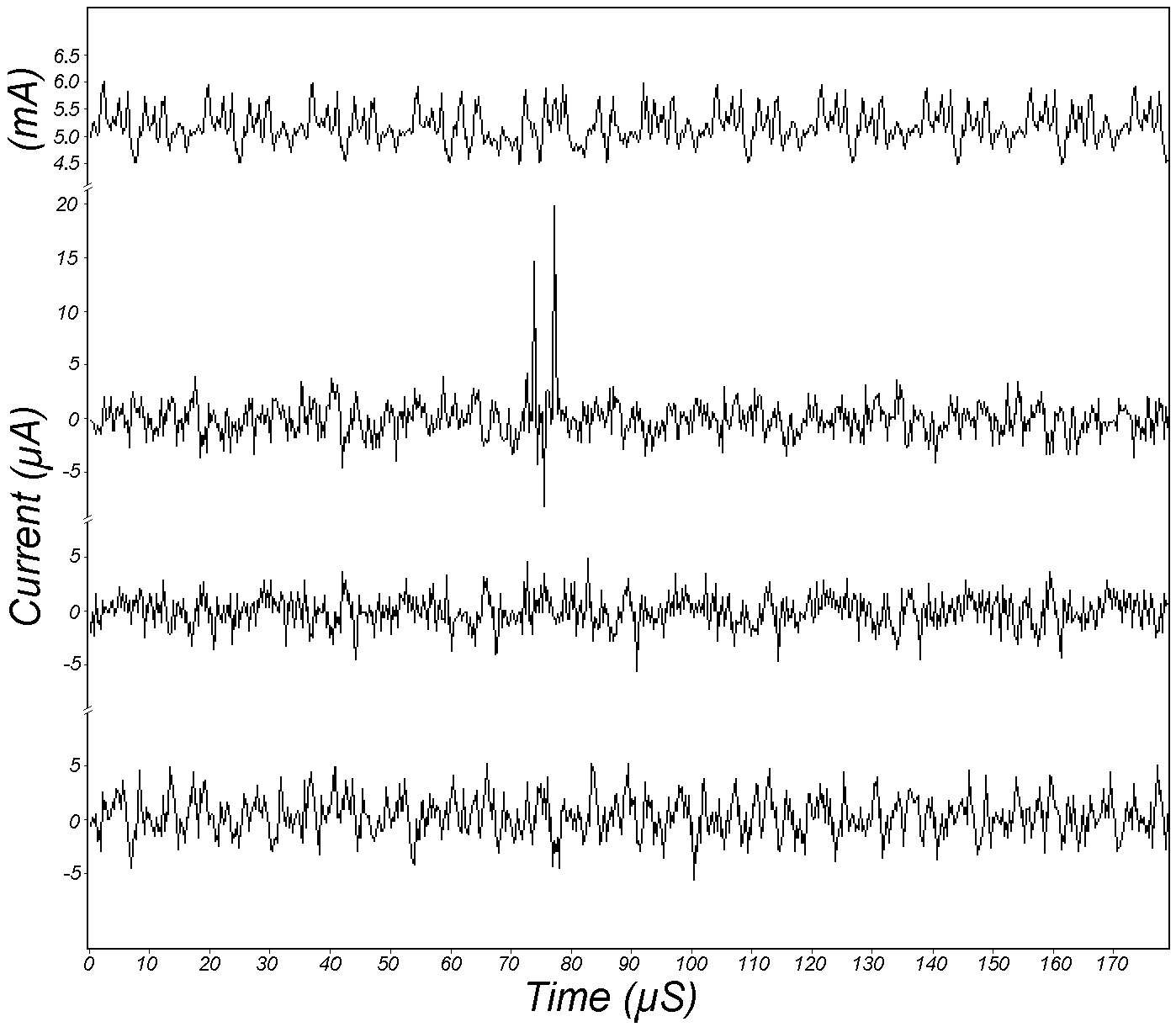 References
| ||||
![\Delta_m[j] \triangleq \dfrac{\sum_{i=1}^m D(C_i,b,K_s)\vec{T}_i[j]}{\sum_{i=1}^m D(C_i,b,K_s)} - \dfrac{\sum_{i=1}^m [1-D(C_i,b,K_s)]\vec{T}_i[j]}{\sum_{i=1}^m [1-D(C_i,b,K_s)]},](https://lo.unisa.edu.au/filter/tex/pix.php/736d69d9fa8f066a9f809190f7c44753.gif "\Delta_m[j] \triangleq \dfrac{\sum_{i=1}^m D(C_i,b,K_s)\vec{T}_i[j]}{\sum_{i=1}^m D(C_i,b,K_s)} - \dfrac{\sum_{i=1}^m [1-D(C_i,b,K_s)]\vec{T}_i[j]}{\sum_{i=1}^m [1-D(C_i,b,K_s)]},")

")





![\vec{T}_i[j]](https://lo.unisa.edu.au/filter/tex/pix.php/61549829655dfd88a160b951b80f1094.gif "\vec{T}_i[j]")


![\lim_{m\to\infty}\Delta_m[j] = 0](https://lo.unisa.edu.au/filter/tex/pix.php/c2639ccee60018577e6b520bb06d4b71.gif "\lim_{m\to\infty}\Delta_m[j] = 0")
![\Delta_m[j_b]](https://lo.unisa.edu.au/filter/tex/pix.php/a926c5e378adc9c88eaffff156066c43.gif "\Delta_m[j_b]")


![\Delta_m[j]](https://lo.unisa.edu.au/filter/tex/pix.php/e2e2264203d8da66fd902df063843c28.gif "\Delta_m[j]")

Diffie-Hellman key agreement | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
The Diffie-Hellman (D-H) key agreement (often called “key exchange”) protocol is standardised in NIST SP 800-56A [BCR+18]. The protocol originated in the seminal 1976 paper by Whitfield Diffie and Martin Hellman [DH76], both recipients of the 2016 Turing Award (their contribution took 40 years to be recognised). Protocol between 👩 Alice and 🧔 Bob [KL21, CONSTRUCTION 11.2] in Fig. 1:
Successful completion of the protocol results in the session key .  A necessary condition for preventing a probabilistic polynomial-time (PPT) eavesdropper from computing the session key is that the computational Diffie-Hellman (CDH) problem is hard: Definition 1: Computational Diffie-Hellman (CDH) problem [Gal12, Definition 20.2.1]
Given the triple of elements of , compute . However, the hardness of the CDH problem is not sufficient. Just as indistinguishability plays an essential role in symmetric-key encryption, indistinguishability is key here: if the session key is indistinguishable from an element chosen uniformly at random from , then we have a sufficient condition for preventing a PPT eavesdropper from computing the session key [KL21, pp. 393-394]. The indistinguishability condition is equivalent to the assumption that the decisional Diffie-Hellman (DDH) problem is hard: Definition 2: Decisional Diffie-Hellman (DDH) problem [Gal12, Definition 20.2.3]
Given the quadruple of elements of , determine whether or not. The DDH problem is readily reducible to the CDH problem, since any algorithm that solves the CDH can compute and compare it with ; implying the DDH problem is no harder than the CDH problem. In turn, the CDH problem is reducible to the discrete logarithm problem (DLP, see Definition 3), since any algorithm that solves the DLP can compute from , from , and hence ; implying the CDH problem is no harder than the DLP problem. Definition 3: Discrete logarithm problem (DLP) [Gal12, Definition 13.0.1]
Given , where is a multiplicative group, find such that . In other words, the DDH problem can be reduced to the CDH problem, which in turn can be reduced to the DLP; solving the DLP breaks the D-H key agreement protocol. There are multiplicative groups for which the DLP is easy, so it is critical that the right groups are used. A safe-prime group is a cyclic subgroup of the Galois field with prime order , where is called a safe prime; this subgroup has elements [BCR+18, Sec. 5.5.1.1]. NIST [BCR+18, Appendix D] refers to RFC 3526 and RFC 7919 for definitions of safe-prime groups. The D-H key agreement protocol is used in the Internet Key Exchange (IKE) protocol, which is currently at version 2 [KHN+14]. References
| ||||||||||||

")









")









")

")





^\ast")


E |
|---|
Emotet | ||||||
|---|---|---|---|---|---|---|
First identified in 2014 [ANY14], the Emotet malware evolved from a banking Trojan designed to steal sensitive information (including credentials) to a modular, polymorphic, multi-threat downloader for other, more destructive malware [MGB22]. References
| ||||||
Encapsulation Packet Protocol (EPP) | ||||
|---|---|---|---|---|
The Encapsulation Packet Protocol (EPP) is used to transfer protocol data units (PDUs) recognised by CCSDS that are not directly transferred by the Space Data Link Protocols over an applicable ground-to-space, space-to-ground, or space-to-space communications link [CCS20b]. References
| ||||
F |
|---|
Federal Information Processing Standards (FIPS) : An Introduction | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
The Federal Information Processing Standards (FIPS) are standards and guidelines for federal computer systems that are developed by National Institute of Standards and Technology (NIST) in accordance with the Federal Information Security Management Act (FISMA) and approved by the Secretary of Commerce in the US [NIS19]. These standards and guidelines were developed when there were no acceptable industry standards or solutions for a particular government requirement. Although FIPS are developed for use by US government, many in the private sector and even other governments such as Australia voluntarily use these standards. FIPS 180-4 [NIS15] specifies secure hash algorithms SHA-1 and SHA-2. SHA-2 is the family of algorithms consisting of SHA-224, SHA-256, SHA-384, SHA-512, SHA-512/224 and SHA-512/256. A hash function produces a condensed representation of a message called a message digest. Since any change to the message results, with an overwhelmingly high probability, in a different message digest, hash functions enable the determination of a message’s integrity. This property is further useful in the generation and verification of digital signatures and message authentication codes, and in the generation of random bits or numbers. For example, software of large sizes such as Linux distributions are typically distributed along with a SHA-256 digest. Available here is an example of how we can verify the integrity of an ISO file. Linux platforms come with the utility Get-FileHash c:\windows\system32\cmd.exe -Algorithm SHA256
FIPS 186-4 [NIS13] specifies three digital signature schemes, namely Digital Signature Algorithm (DSA), RSA digital signature algorithm and Elliptic Curve Digital Signature Algorithm (ECDSA). FIPS 197 [NIS01] specifies the block cipher Advanced Encryption Standard (AES). FIPS 198 [NIS08] specifies the Keyed-Hash Message Authentication Code (HMAC). References
| ||||||||||||
Flow | ||
|---|---|---|
H |
|---|
Hardware Trojan | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
A hardware Trojan (see Definition 1) may control, modify, disable, or monitor the contents and communications of the device it is embedded in [RKK14, Sec. II]. Hardware that has been modified with a malicious functionality hidden from the user. Hardware Trojans provide a means to bypass traditional software and cryptographic-based protections, allowing a malicious actor to control or manipulate device/system software, 1️⃣ getting access to sensitive information, and/or 2️⃣ causing denial-of-service to legitimate users by causing device/system failures or simply by turning the device/system off [BDF+22]. Examples of hardware Trojans are aplenty within academia and outside of academia [HAT21].
👩🎓 Examples from within academia Smartphones often break, but replacing broken components provides an opportunity for malicious actors to implant hardware Trojans. One of the most frequently replaced components is the touchscreen; more than 50% of smartphone owners have damaged their screen at least once [SCSO17]. Steps of the “Shattered Trust” attack [SCSO17]:
Another frequently replaced component is the phone battery [LFH+18] 🎦. On a larger scale, computer peripherals can serve as hardware Trojans that exploit the vulnerabilities in Input-Output Memory Management Units (IOMMUs) [MRG+19].
 Watch Christof Paar’s overview lecture:
👩💻 Examples from outside academia In 2018, Bloomberg Businessweek made the sensational claim entitled “The Big Hack” that China’s PLA launched a supply chain attack by implanting a tiny Trojan chip in motherboards made by Super Micro Computer Inc. (“Supermicro” for short) [MLP+20] 🎦.
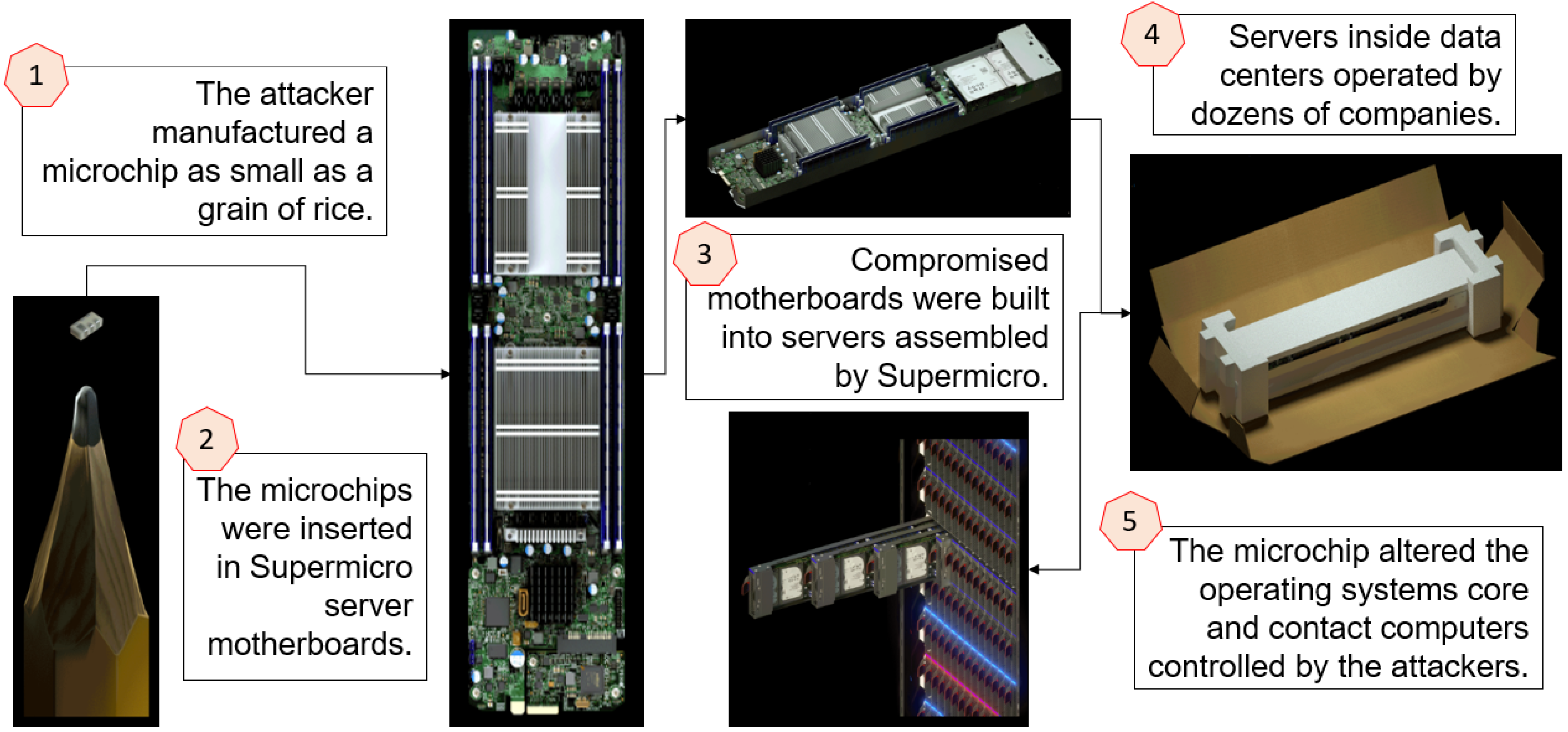
Trojan detection is challenging because [RKK14, Sec. II]:
CountermeasuresFour main defence strategies can be identified [HAT21, Sec. 4]:
References
| ||||||||||||||||||||||||||||
















Hash functions | |||
|---|---|---|---|
See 👇 attachment.
| |||
Homodyne vs heterodyne detection | ||||
|---|---|---|---|---|
Homodyne detection = method of detecting a weak frequency-modulated signal through mixing with a strong reference frequency-modulated signal (so-called local oscillator). References
| ||||
I |
|---|
Intrusion detection: an introduction | ||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
NIST defines intrusion detection to be: Definition 1: Intrusion detection [SM07, Appendix A]
The process of monitoring the events occurring in a computer system or network and analysing them for signs of possible incidents. Intrusion prevention goes beyond intrusion detection, although “prevention” is strictly speaking an exaggeration: Definition 2: Intrusion prevention [SM07, Appendix A]
The process of monitoring the events occurring in a computer system or network, analysing them for signs of possible incidents, and attempting to stop detected possible incidents. In Definition 2, an “attempt” can be sending an alarm to the administrator(s), resetting a network connection, reconfiguring a firewall to block traffic from the source address, etc. Thus, “intrusion detection and prevention system” (IDPS) is synonymous with “intrusion prevention system” (IPS) [SM07, Appendix A], and is a bit of a redundant term. Fig. 1 shows an example of a high-end IPS appliance from Cisco.  In the 1970s and the early 1980s, administrators had to print out system logs on papers and manually audit the printout [KV02]. The process was clearly 1️⃣ reliant on the auditors’ expertise, 2️⃣ time-consuming, and 3️⃣ too slow to detect attacks in progress. In the 1980s, storage became cheaper, and intrusion detection programs became available for analysing audit logs online, but the programs could only be run at night when the system’s user load was low [KV02]. Thus, detecting attacks in time remained a challenge. In the early 1990s, real-time intrusion detection systems (IDSs) that analysed audit logs as the logs were produced became available [KV02]. Since the inception of IDSs, the quality and quantity of audit logs have always been a challenge [KV02]:
An IDS is meant to detect [KV02]:
Accordingly, intrusion detection algorithms can be classified as [SM07; YT11, p. 2; BK14, p. 4; Led22; Pal22]:
Depending on its type, an IDS can comprise several types of components, as shown in Fig. 2: sensors/agents (which monitor and analyse network activities and may also perform preventive actions), management servers, database servers, user and administrator consoles, and management networks [SM07]. There is more than one way to classify IDSs. See the attachment for different classifications of IDSs. Watch the following LinkedIn Learning video for a quick summary of IDS: What is an IDS? from Protecting Your Network with Open Source Software by Jungwoo Ryoo References
| ||||||||||||||||||||||||||||||||||||||||||||||

Intrusion detection systems: classifications | |||
|---|---|---|---|
See attachment 👇. | |||
J |
|---|
JTAG | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
The increasing usage of cutting-edge technologies in safety-critical applications leads to strict requirements on the detection of defects both at the end of manufacturing and in the field [VDSDN+19]. Besides scan chains, test access ports (TAPs) and associated protocols constitute the fundamental test mechanism [VDSDN+19]. Among the earliest standards for test access ports is IEEE Std 1149.1a-1993, first drafted by the Joint Test Action Group (JTAG) in the late 1980s, and then standardised by the IEEE in the early 1990s [IEEE13].
Fig. 1: The boundary scan architecture [BT19, FIGURE 3.19]. Note: TDI = test data input; TMS = test mode select; TCK = test clock input; TRST = test reset; TDO = test data output. The boundary-scan register cells for the pins of a component are interconnected to form a shift-register chain around the border of the design, and this path is provided with serial input and output connections as well as appropriate clock and control signals [IEEE13, Sec. 1.2.3]. 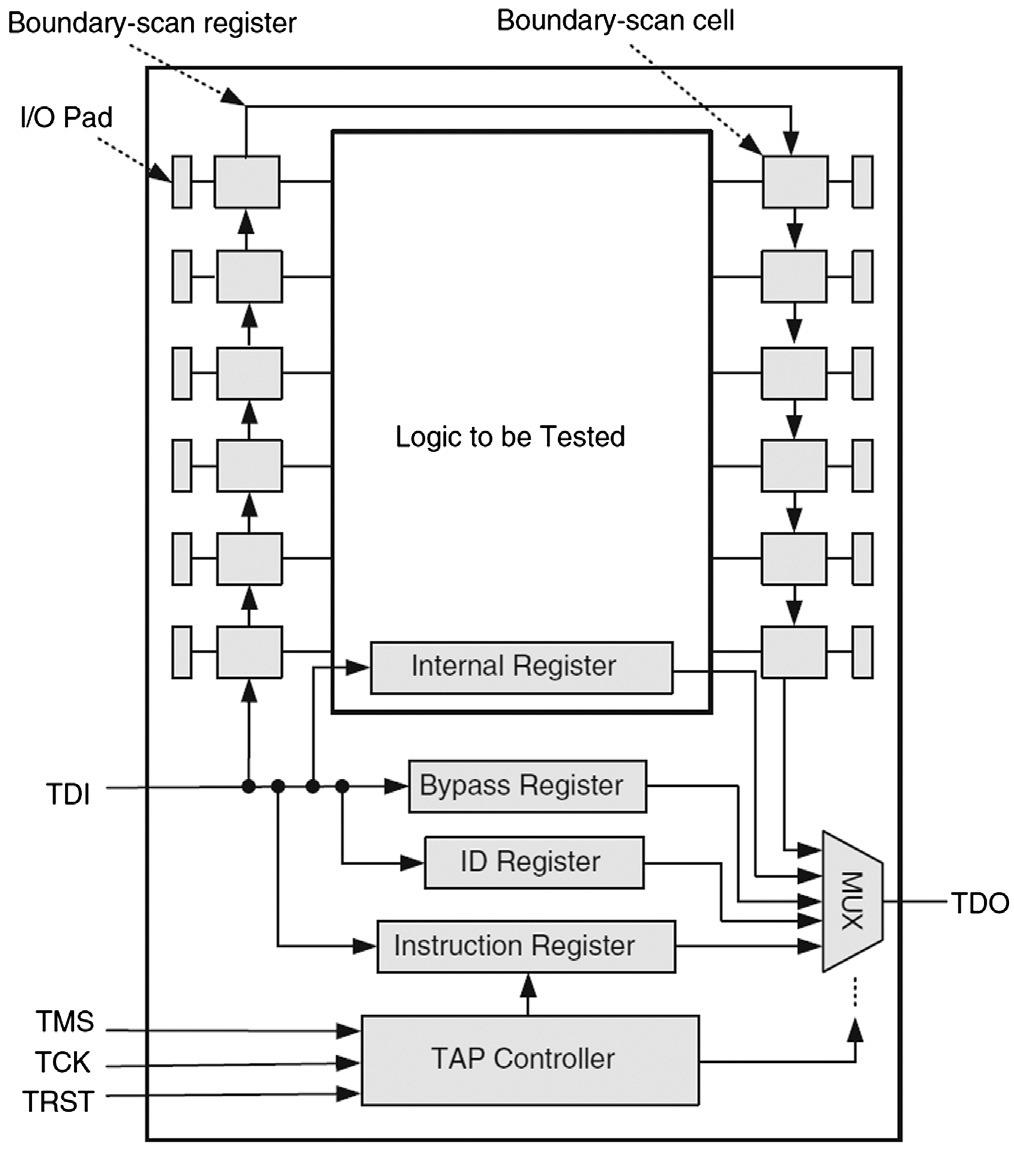 Fig. 2: A sample boundary-scan register cell [IEEE13, Figure 1-1]. If used for an input, data can either be loaded into the scan register from the input pin through the “Signal In” port, or be driven from the register through the “Signal Out” port of the cell into the core of the component design, depending on the control signals applied to the multiplexers (see Fig. 1). If used for an an output, data can either be loaded into the scan register from the core of the component, or be driven from the register to an output pin.  The TAP controller in Fig. 1 implements the 16-state finite state machine in Fig. 3. For example, Select-DR-Scan is a temporary controller state (i.e., the next rising edge of TCK makes the controller exit this state) in which all test data registers (DRs) selected by the current instruction retain their previous state [IEEE13, p. 26].
 Operationally speaking, the most important consideration for a security analyst, when assessing the security of a device, is finding a JTAG interface. Standard tools such as the Bus Pirate, JTAGulator and Open On-Chip Debugger (OpenOCD) can then be used to probe the device through this interface. Watch the following tutorial on YouTube: References
| ||||||||||||||
K |
|---|
Key establishment and key management | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
Key establishment (see Definition 1) is part of key management (see Definition 2). Definition 1: Key establishment [MvV96, Definition 1.63]
A process whereby a shared secret key becomes available to two or more parties, for subsequent cryptographic use. Definition 2: Key management [BB19, p. 12]
Activities involved in the handling of cryptographic keys and other related parameters (e.g., IVs and domain parameters) during the entire life cycle of the keys, including their generation, storage, establishment, entry and output into cryptographic modules, use and destruction. Simply speaking, key management is a set of processes and mechanisms which support key establishment and the maintenance of ongoing keying relationships between parties, including replacing older keys with new keys as necessary [MvV96, Definition 1.64]; see Fig. 1.  Example 1
Key management includes identification of the key types. CCSDS [CCS11] has identified the following key types for securing space missions:
Key establishment can be broadly classified into key agreement (see Definition 3) and key transport (see Definition 4). Definition 3: Key agreement [BB19, p. 11]
A pair-wise key-establishment procedure in which the resultant secret keying material is a function of information contributed by both participants, so that neither party can predetermine the value of the secret keying material independently from the contributions of the other party. 👩 ➡ 🔑 ⬅ 🧔 Definition 4: Key transport [BB19, p. 14]
A key-establishment procedure whereby one entity (the sender) selects a value for secret keying material and then securely distributes that value to one or more other entities (the receivers). 👩 ➡ 🔑 ➡ 👨👩👧👦 Key agreement is more popular than key transport, and the de facto standard key agreement protocol is Diffie-Hellman key agreement. References
| ||||||||||
L |
|---|
Licklider Transmission Protocol (LTP) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
CCSDS has adopted the Licklider Transmission Protocol (LTP) as specified in the IETF RFC 5326 [BFR08b] and the associated security extensions specified in IETF RFC 5327 [BFR08a] to provide reliability and authentication mechanisms on top of an underlying (usually data link) communication service [CCS15b, Sec. 1.1]. In an Interplanetary Internet setting deploying the Bundle Protocol [BFR08b], LTP is intended to serve as a reliable “convergence layer” protocol operating in pairwise fashion between adjacent in-range Interplanetary Internet nodes. LTP aggregates multiple layer-(N+1) PDUs into a single layer-N PDU for reliable delivery — this allows the system to reduce the acknowledgement-channel bandwidth in the case that the layer-(N+1) (and higher) protocols transmit many small PDUs, each of which might otherwise require independent acknowledgement; see Fig. 1. In CCSDS settings [CCS15b, Sec. 1.2], LTP is intended for use over package delivery services including packet telecommand and packet telemetry. For space links, LTP is typically deployed over a CCSDS data link that supports CCSDS Encapsulation Packets so that one LPT segment can be encapsulated in a single Encapsulation Packet. LTP can also operate over ground-network services, in which case it is usually deployed over UDP; see Fig. 2. Fig. 1: To protocols above LTP (e.g., Bundle Protocol), LTP enables reliable delivery of layer-(N+1) PDUs across a link [CCS15b, Figure 1-1]. For LTP, the interface to the data link is via either direct encapsulation in CCSDS Space Packets or the CCSDS Encapsulation Service.   References
| ||||||||||
M |
|---|
Meltdown attacks | ||||||
|---|---|---|---|---|---|---|
Out-of-order execution is a prevalent performance feature of modern processors for reducing latencies of busy execution units, e.g., a memory fetch unit waiting for data from memory: instead of stalling execution, a processor skips ahead and executes subsequent instructions [LSG+18]. See Fig. 1. Fig. 1: If an executed instruction causes an exception that diverts the control flow to an exception handler, the subsequent instruction must not be executed [LSG+18, Figure 3]. Due to out-of-order execution, the subsequent instructions may already have been partially executed, but not retired. However, architectural effects of the execution are discarded.  Although the instructions executed out of order do not have any visible architectural effect on the registers or memory, they have microarchitectural side effects [LSG+18, Sec. 3].
Meltdown consists of two building blocks [LSG+18, Sec. 4], as illustrated in Fig. 2:
Operation-wise, Meltdown consists of 3 steps [LSG+18, Sec. 5.1]:
Fig. 2: The Meltdown attack uses exception handling or suppression, e.g., TSX (disabled by default since 2021), to run a series of transient instructions [LSG+18, Figure 5]. The covert channel consists of 1️⃣ transient instructions obtaining a (persistent) secret value and changing the microarchitectural state of the processor based on this secret value; 2️⃣ FLUSH+RELOAD reading the microarchitectural state, making it architectural and recovering the secret value.  Watch the presentation given by one of the discoverers of Meltdown attacks at the 27th USENIX Security Symposium: Since FLUSH+RELOAD was mentioned, watch the original presentation at USENIX Security ’14: More information on the Meltdown and Spectre website. References
| ||||||

MITRE ATLAS | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
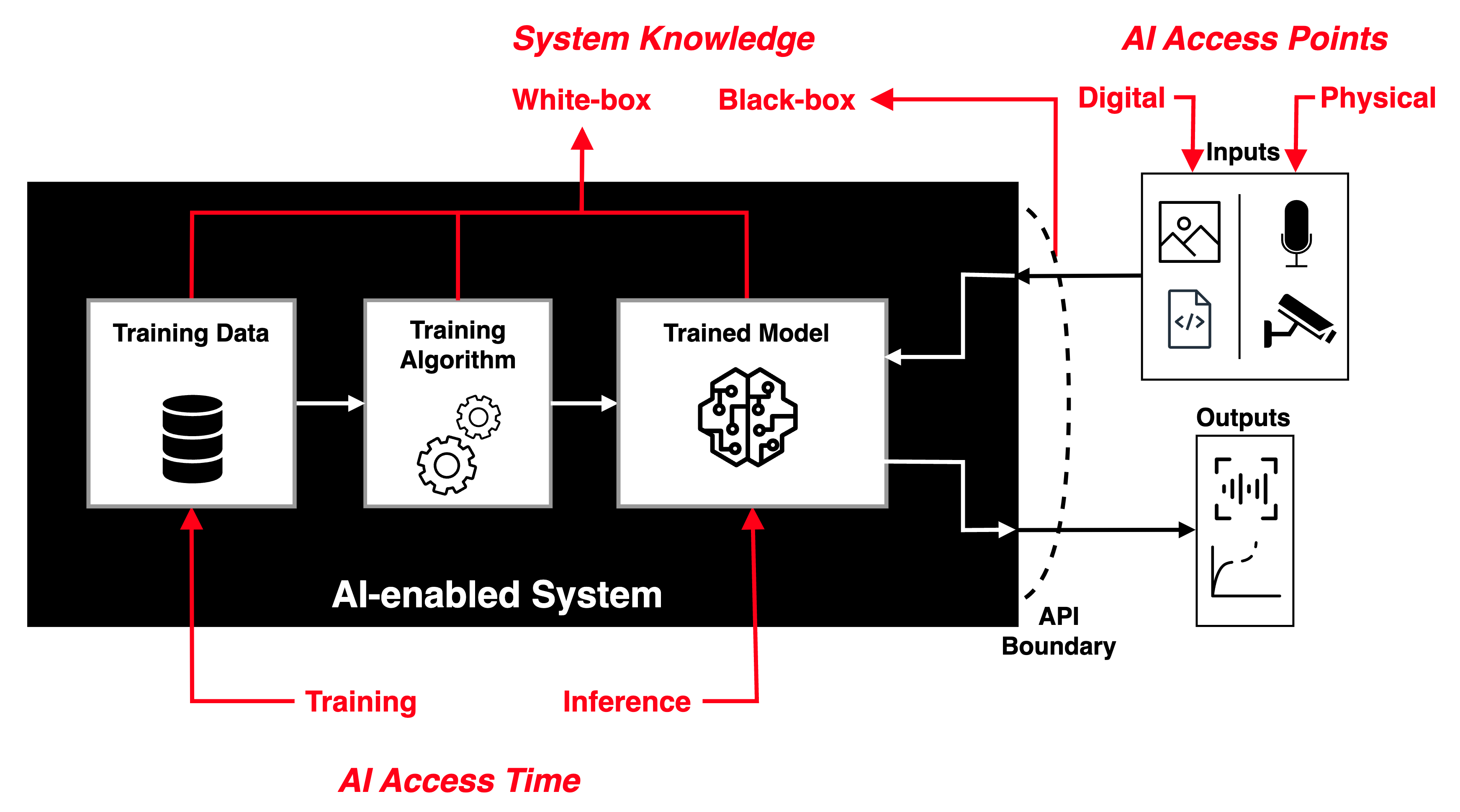
The field of adversarial machine learning (AML) is concerned with the study of attacks on machine learning (ML) algorithms and the design of robust ML algorithms to defend against these attacks [TBH+19, Sec. 1]. ML systems (and by extension AI systems) can fail in many ways, some more obvious than the others. AML is not about ML systems failing when they make wrong inferences; it is about ML systems being tricked into making wrong inferences. Consider three basic attack scenarios on ML systems: Black-box evasion attack: Consider the most common deployment scenario in Fig. 1, where an ML model is deployed as an API endpoint.
White-box evasion attack: Consider the scenario in Fig. 1, where an ML model exists on a smartphone or an IoT edge node, which an adversary has access to.
Poisoning attacks: Consider the scenario in Fig. 1, where an adversary has control over the training data, process and hence the model.
Watch introduction to evasion attacks (informally called “perturbation attacks”) on LinkedIn Learning: Perturbation attacks and AUPs from Security Risks in AI and Machine Learning: Categorizing Attacks and Failure Modes by Diana Kelley Watch introduction to poisoning attacks on LinkedIn Learning: Poisoning attacks from Security Risks in AI and Machine Learning: Categorizing Attacks and Failure Modes by Diana Kelley In response to the threats of AML, in 2020, MITRE and Microsoft, released the Adversarial ML Threat Matrix in collaboration with Bosch, IBM, NVIDIA, Airbus, University of Toronto, etc. Subsequently, in 2021, more organisations joined MITRE and Microsoft to release Version 2.0, and renamed the matrix to MITRE ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems). MITRE ATLAS is a knowledge base — modelled after MITRE ATT&CK — of adversary tactics, techniques, and case studies for ML systems based on real-world observations, demonstrations from ML red teams and security groups, and the state of the possible from academic research. Watch MITRE’s presentation: References
| ||||||||||

MITRE ATT&CK | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
MITRE ATT&CK® is a knowledge base of adversary tactics (capturing “why”) and techniques (capturing “how”) based on real-world observations. There are three versions [SAM+20]: 1️⃣ Enterprise (first published in 2015), 2️⃣ Mobile (first published in 2017), and 3️⃣ Industrial Control System (ICS, first published in 2020). Fig. 1 below shows the fourteen MITRE ATT&CK Enterprise tactics: 
The Mobile tactics and ICS tactics are summarised below. Note a tactic in the Mobile context is not the same as the identically named tactic in the ICS context.
Among the tools that support the ATT&CK framework is MITRE CALDERA™ (source code on GitHub).
A (blurry) demo is available on YouTube: A complementary model to ATT&CK called PRE-ATT&CK was published in 2017 to focus on “left of exploit” behavior [SAM+20]:
ATT&CK is not meant to be exhaustive, because that is the role of MITRE Common Weakness Enumeration (CWE™) and MITRE Common Attack Pattern Enumeration and Classification (CAPEC™) [SAM+20].
References
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
MITRE CAPEC | |||
|---|---|---|---|
MITRE’s Common Attack Pattern Enumeration and Classification (CAPEC™) effort provides a publicly available catalogue of common attack patterns to help users understand how adversaries exploit weaknesses in applications and other cyber-enabled capabilities. Attack patterns are descriptions of the common attributes and approaches employed by adversaries to exploit known weaknesses in cyber-enabled capabilities.
As of writing, CAPEC stands at version 3.9 and contains 559 attack patterns. For example, CAPEC-98 is phishing: Definition 1: Phishing
A social engineering technique where an attacker masquerades as a legitimate entity with which the victim might interact (e.g., do business) in order to prompt the user to reveal some confidential information (typically authentication credentials) that can later be used by an attacker. CAPEC-98 can be mapped to CWE-451 “User Interface (UI) Misrepresentation of Critical Information”. | |||
MITRE D3FEND | ||||
|---|---|---|---|---|
MITRE D3FEND is a knowledge base — more precisely a knowledge graph — of cybersecurity countermeasures/techniques, created with the primary goal of helping standardise the vocabulary used to describe defensive cybersecurity functions/technologies.
The D3FEND knowledge graph was designed to map MITRE ATT&CK techniques (or sub-techniques) through digital artefacts to defensive techniques; see Fig. 1.
 Operationally speaking, the D3FEND knowledge graph allows looking up of defence techniques against specific MITRE ATT&CK techniques.
Watch an overview of the D3FEND knowledge graph from MITRE on YouTube: References
| ||||

MITRE Engage | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
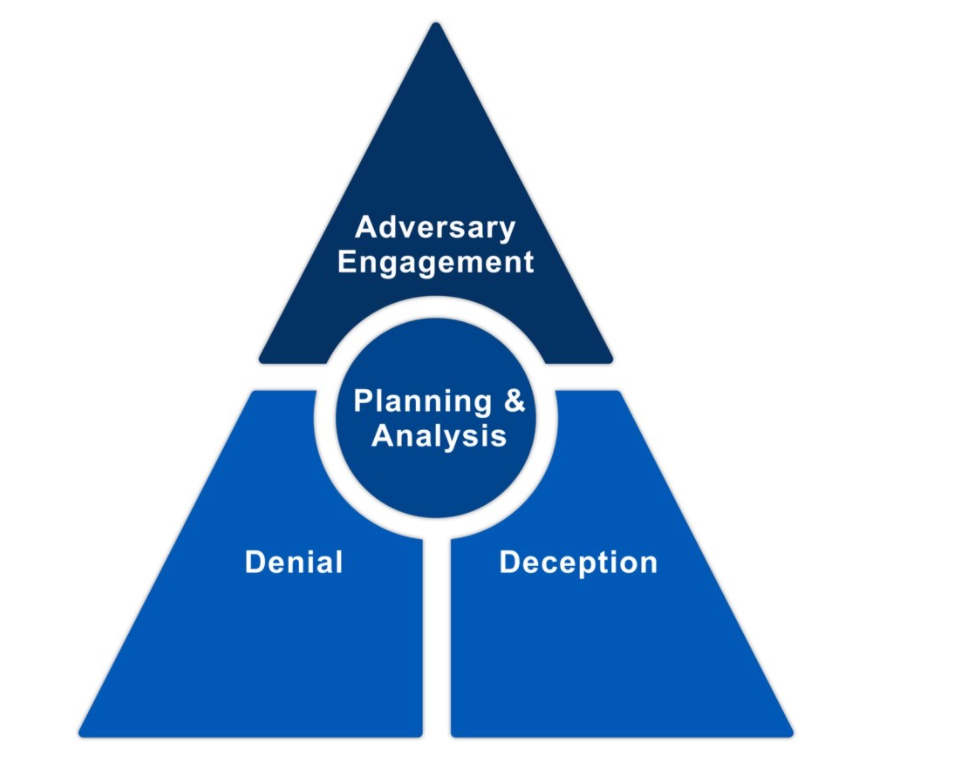
MITRE Engage (previously MITRE Shield) is a framework for planning and discussing adversary engagement operations.
Cyber defense has traditionally focussed on applying defence-in-depth to deny adversaries’ access to an organisation’s critical cyber assets. Increasingly, actively engaging adversaries proves to be more effective defence [MIT22b].
The foundation of adversary engagement, within the context of strategic planning and analysis, is cyber denial and cyber deception [MIT22b]:
While MITRE Engage has not been around for long, the practice of cyber deception has a long history; honeypots for example can be traced back to the 1990s [Spi04, Ch. 3]. MITRE Engage prescribes the 10-Step Process, which was adapted from the process of deception in [RW13, Ch. 19], in Fig. 1:  Prepare phase:
Operate phase:
Understand phase:
Example 1: The Tularosa Study
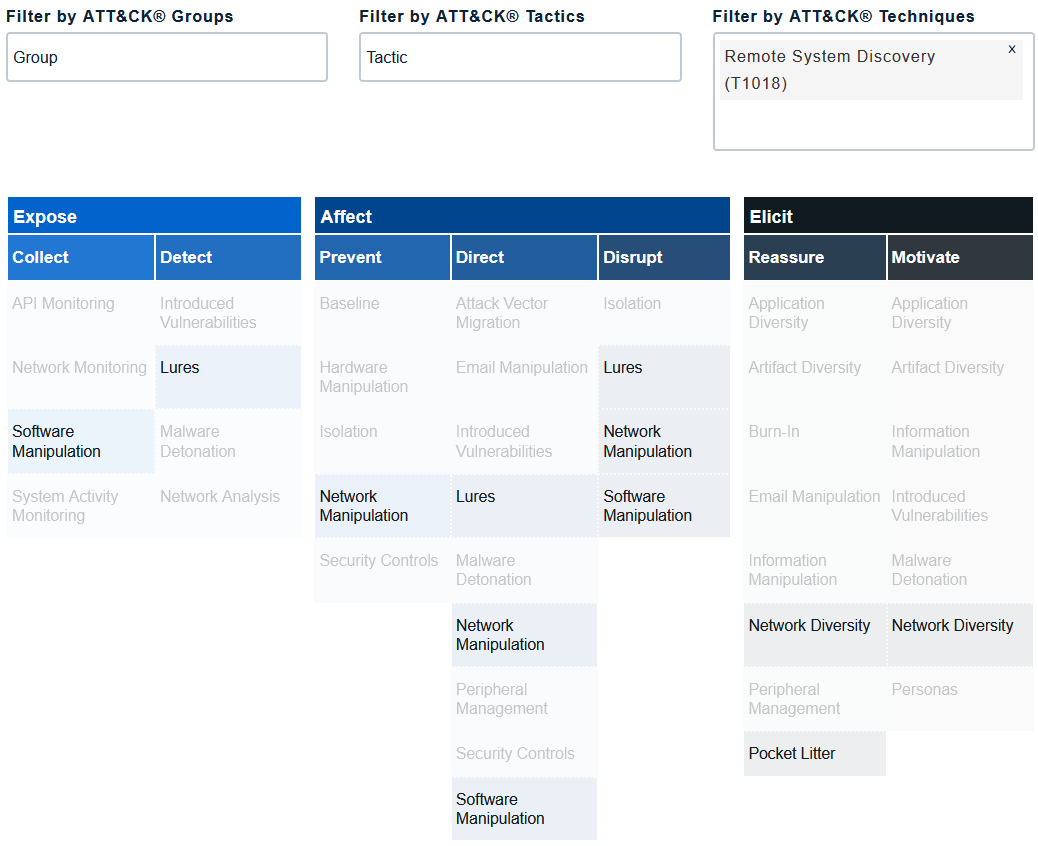
A starting point to practising cyber deception is to combine deception tools (e.g., honeypots and decoy content) with traditional defences (e.g., application programming interface monitoring, backup and recovery) [Heb22]. Contrary to intuition, cyber deception is more effective when adversaries know it is in place, because its presence exerts psychological impact on the adversaries [Heb22]. Supporting evidence is available from the 2018 Tularosa Study [FWSR+18]; watch presentation below: Operationalise the MethodologiesThe foundation of an adversary engagement strategy is the Engage Matrix: The Matrix serves a shared reference that bridges the gap between defenders and decision makers when discussing and planning denial, deception, and adversary engagement activities. The Matrix allows us to apply the theoretical 10-Step Process (see Fig. 1) to an actual operation. The top row identifies the goals: Prepare and Understand, as well as the objectives: Expose, Affect and Elicit.
The second row identifies the approaches, which let us make progress towards our selected goal. The remainder of the Matrix identifies the activities.
References
| ||||||||||||


Model checking | ||||||
|---|---|---|---|---|---|---|
Model checking is a method for formally verifying that a model satisfies a specified property [vJ11, p. 1255]. Model checking algorithms typically entail enumerating the program state space to determine if the desired properties hold. Example 1 [CDW04]
Developed by UC Berkeley, MOdelchecking Programs for Security properties (MOPS) is a static (compile-time) analysis tool, which given a program and a security property (expressed as a finite-state automaton), checks whether the program can violate the security property. The security properties that MOPS checks are temporal safety properties, i.e., properties requiring that programs perform certain security-relevant operations in certain orders. An example of a temporal security property is whether a setuid-root program drops root privileges before executing an untrusted program; see Fig. 1.  References
| ||||||
N |
|---|
NIST Cybersecurity Framework | ||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
The National Institute of Standards and Technology (NIST) has an essential role in identifying and developing cybersecurity risk frameworks for voluntary use by owners and operators of critical infrastructure (see Definition 1) [NIS18, Executive Summary]. Definition 1: Critical infrastructure [NIS18, Sec. 1.0]
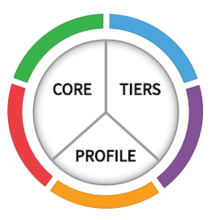
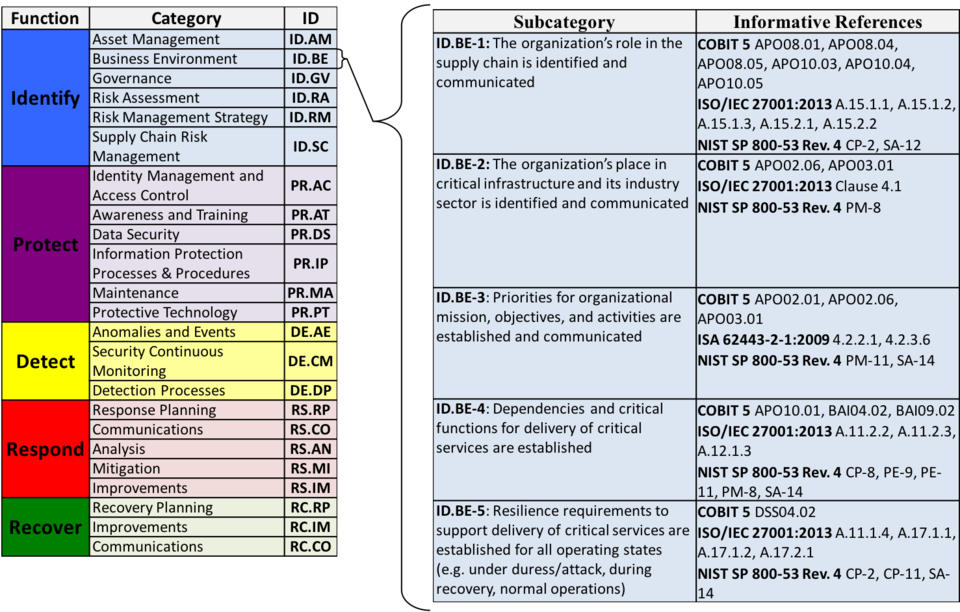
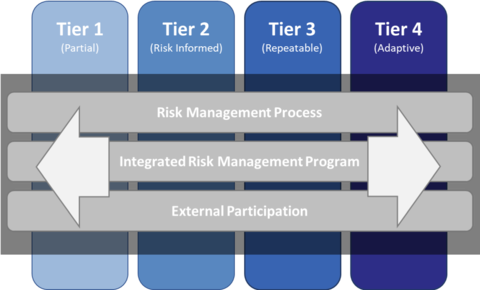
Systems and assets, whether physical or virtual, so vital that the incapacity or destruction of such systems and assets would have a debilitating impact on security, national economic security, national public health or safety, or any combination of those matters. One such framework is the Framework for Improving Critical Infrastructure Cybersecurity (Cybersecurity Framework for short), for which NIST is maintaining an official website. As of writing, the latest version of the NIST Cybersecurity Framework is 1.1 [NIS18]. The Cybersecurity Framework provides a common language for understanding, managing and expressing cybersecurity risks to internal and external stakeholders [NIS18, Sec. 2.0]. The Cybersecurity Framework has three parts: 1️⃣ Framework Core, 2️⃣ Implementation Tiers, and 3️⃣ Framework Profiles.
Watch a more detailed explanation of the Cybersecurity Framework presented at RSA Conference 2018: References
| ||||||||||||||||||||||||||||||

O |
|---|
Open Systems Interconnection (OSI) | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Imagine writing a piece of networking software.
The Open Systems Interconnection (sometimes Open Systems Interconnect or simply OSI) model 1️⃣ enables networking software to be built in a structured manner; 2️⃣ provides an interoperability framework for networking protocols. History: The OSI model was introduced in 1983 by several major computer and telecom companies; and was adopted by ISO as an international standard in 1984 [Imp22].
Watch the following video for a quick overview: Learning the seven layers from Networking Foundations: Networking Basics by Kevin Wallace More details follows. The OSI model is a logical (as opposed to physical) model that consists of seven nonoverlapping layers (going bottom-up, opposite to Fig. 1):
 
The OSI model is not the only networking model. The TCP/IP reference model plays an equally important role in the history of networking. The APRANET and its descendent — the Internet as we know it — are based on the TCP/IP model. The TCP/IP model has only four layers, as shown in Fig. 3. Fig. 3 also shows the different protocols occupying the different layers of the TCP/IP model. Both models use 1️⃣ the transport and lower layers to provide an end-to-end, network-independent transport service; and 2️⃣ the layers above transport for applications leveraging the transport service. Most real-world protocol stacks are developed based on a hybrid of the OSI and TCP/IP models, consisting of these layers (from bottom to top): physical, data link, network, transport, application [TW11, Sec. 1.4.3]. 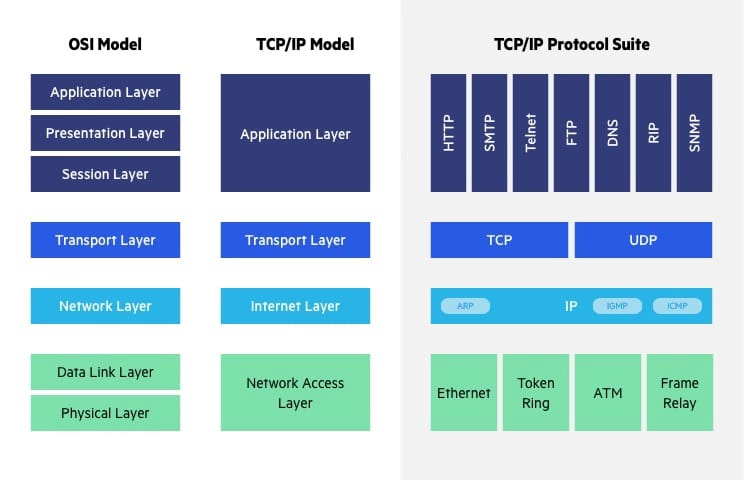 The salient differences between the OSI and TCP/IP models are summarised in Table 1 below.
References
| ||||||||||||||||||||||||||||
P |
|---|
Physical-layer security | ||||
|---|---|---|---|---|
References
| ||||
Physical unclonable function (PUF) | ||||
|---|---|---|---|---|
Physical unclonable functions (PUFs, see Definition 1) serve as a physical and unclonable alternative to digital cryptographic keys. Definition 1: Physical unclonable function (PUF) [GASA20]
A device that exploits inherent randomness introduced during manufacturing to give a physical entity a unique “fingerprint” or trust anchor. Think of a PUF as a keyed hash function, where the key is built-in and unique due to manufacturing variations [GASA20].
Types of PUFs include 1️⃣ optical PUFs, 2️⃣ arbiter PUFs, 3️⃣ memory-based intrinsic PUFs [GASA20].
Watch a high-level introduction to SRAM PUF: References
| ||||
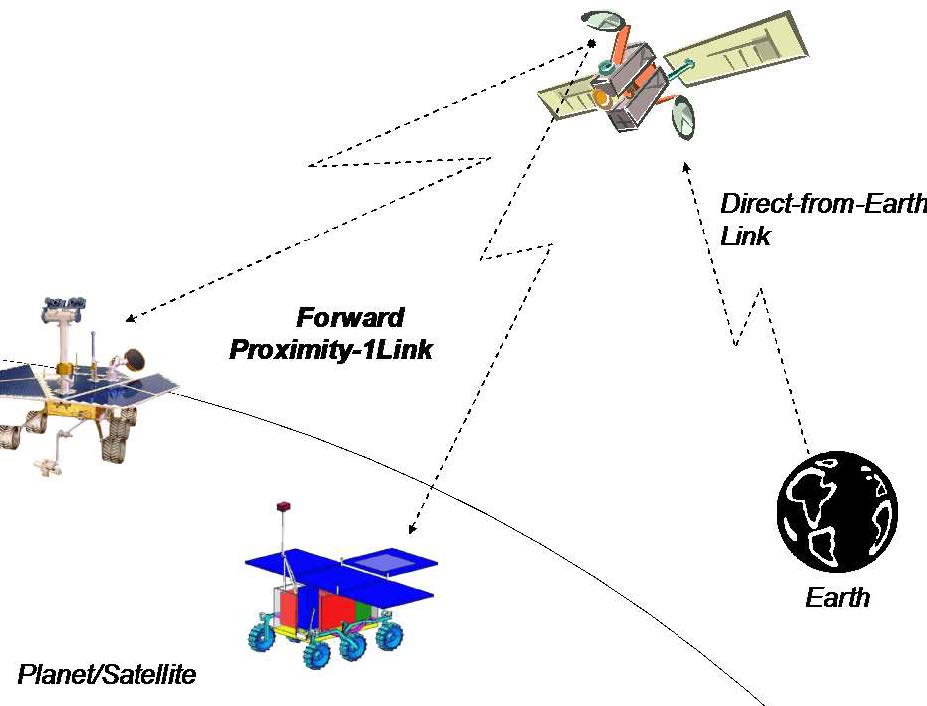
Proximity-1 Space Link Protocol | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
Proximity-1 covers the data link layer [CCS20d] and physical layer [CCS13b]. Proximity-1 enables communications among probes, landers, rovers, orbiting constellations, and orbiting relays in a proximate environment, up to about 100,000 km [CCS13c]. These scenarios are devoid of manual intervention from ground operators, and furthermore, resources such as computational power and storage are typically limited at both ends of the link. In fact, Proximity-1 has been field-tested in the 2004-2005 Mars missions; see Figs. 1-2 for illustration.
In contrast, the AOS/TC/TM Space Data Link Protocols are meant for Earth-deep space links, over extremely long distances. Proximity-1 supports symbol rates of up to 4,096,000 coded symbols per second. Designed for the Mars environment, the physical Layer of Proximity-1 only uses UHF frequencies [CCS13b, Sec. 1.2]. The frequency range consists of 60 MHz between 390 MHz to 450 MHz with a 30 MHz guard-band between forward and return frequency bands, specifically 435-450 MHz for the forward channel and 390-405 MHz for the return channel [CCS13b, Sec. 3.3.2]. References
| ||||||||||||

Public-key cryptography | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
Also known as asymmetric-key cryptography, public-key cryptography (PKC) uses a pair of keys called a public key and a private key for 1️⃣ encryption and decryption, as well as 2️⃣ signing and verification. Encryption and decryption For 👩 Alice to send a confidential message to 🧔 Bob,
However,
Signing and verification For 👩 Alice to assure 🧔 Bob a message really originated from her (i.e., for Bob to authenticate her message),
Definition 1: Non-repudiation [NIS13]
A service that is used to provide assurance of the integrity and origin of data in such a way that the integrity and origin can be verified and validated by a third party as having originated from a specific entity in possession of the private key (i.e., the signatory). The ability of PKC to generate and verify signatures gives rise to 📜 digital certificates, an essential feature of PKC. Digital certificates and public-key infrastructure (PKI)Suppose 👩 Alice is somebody everybody trusts.
Definition 3: Digital certificate [ENISA]
Also called a public-key certificate, a digital certificate is an electronic data structure that binds an entity (e.g., an institution, a person, a computer program, a web address) to its public key. Watch a quick introduction to digital certificates on LinkedIn Learning: Digital certificates and signing from Ethical Hacking: Cryptography by Stephanie Domas Digital certificates are only useful if we can trust their signatories. To ensure signatories and hence certificates can be trusted, PKC relies on a public-key infrastructure (PKI, see Definition 3) to work. Definition 3: Public-key infrastructure (PKI)
In ENISA’s certificate-centric definition, a PKI is a combination of policies, procedures and technology needed to manage digital certificates in a PKC scheme. In ITU-T’s [ITU19] key-centric definition, a PKI is an infrastructure able to support the management of public keys able to support authentication, encryption, integrity and non-repudiation services. Watch a quick introduction to PKI from an operational viewpoint on LinkedIn Learning: Cryptography: Public key infrastructure and certificates from CISA Cert Prep: 5 Information Asset Protection for IS Auditors by Human Element LLC and Michael Lester A PKI, as specified in the ITU-T X.509 [ITU19] standard, consist of certification authorities (CAs).
Fig. 1: A two-tier hierarchy of CAs [NCS20, p. 6]. In a 2-tier hierarchy, a root CA issues certificates to intermediate CAs, and intermediate CAs issue certificates to end entities. Intermediate CAs are often organised to issue certificates for certain functions, e.g., a technology use case, VPN, web application. Alternatively, the CAs can be organised by organisational function, e.g., user / machine / service authentication. 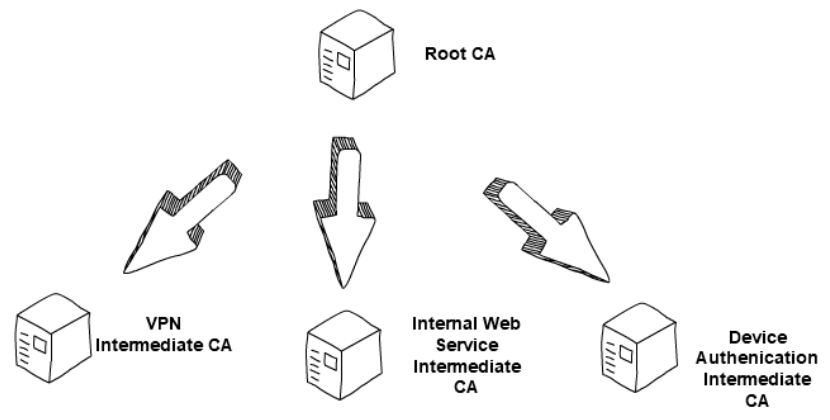 Fig. 2: A three-tier hierarchy of CAs [NCS20, p. 6]. In a 3-tier hierarchy, there is a root CA and two levels of intermediate CAs, in which the lowest layer issues certificates to end entities. This setup is often used to give an extra layer of separation between the root CA and the intermediate issuing certificates to end entities. The number of tiers in a CA hierarchy is a balance between the level of separation required and the tolerable administration overheard.  A PKI also has registration authorities (RAs).
Although the X.509 standard does not specify any validation authority (VA), a VA allows an entity to check that a certificate has not been revoked [NCS20, p. 3].
 Public-key cryptosystemsAlgorithmically speaking, there is more than one way of constructing a public-key cryptosystem. Standard public-key cryptosystems: 1️⃣ Rivest-Shamir-Adleman (RSA) cryptosystem, 2️⃣ elliptic-curve cryptosystems. These cryptosystems rely on the hardness of certain computational problems for their security. The hardness of these computational problems has come under threat of quantum computers and quantum algorithms like Shor’s algorithm. As a countermeasure, NIST has been searching for post-quantum cryptography (PQC, also called quantum-resistant cryptography). As of writing, there are three PQC candidates. References
| ||||||||||

R |
|---|
Rivest-Shamir-Adleman (RSA) cryptosystem | ||
|---|---|---|
See 👇 attachment (coming soon) or the latest source on Overleaf. | ||
Rowhammer | ||||
|---|---|---|---|---|
Not ready for 2023 but see reference below. References
| ||||
S |
|---|
Safe programming languages | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
A safe programming language is one that is memory-safe (see Definition 1), type-safe (see Definition 2) and thread-safe (see Definition 3). Definition 1: Memory safety [WWK+21]
Assurance that adversaries cannot read or write to memory locations other than those intended by the programmer. A significant percentage of software vulnerabilities have been attributed to memory safety issues [NSA22], hence memory safety is of critical importance. Examples of violations of memory safety can be found in the discussion of common weakness CWE-787 and CWE-125. Definition 2: Type safety [Fru07, Sec. 1.1]
Type safety is a formal guarantee that the execution of any program is free of type errors, which are undesirable program behaviours resulting from attempts to perform on some value an operation that is inappropriate to the type of the value. For example, applying a factorial function to any value that is not an integer should result in a type error. Type safety ⇒ memory safety, but the converse is not true [SM07, Sec. 6.5.2], hence type safety is commonly considered to be a central theme in language-based security [Fru07]. Type-safe programming languages, e.g., Java , Ruby, C#, Go, Kotlin, Swift and Rust, have been around for a while. However, memory-unsafe languages are still being used because:
Nevertheless, adoption of type-safe languages, especially Rust, has been on the rise [Cla23]. Thread safety rounds up the desirable properties of type-safe languages. Definition 3: Thread safety [Ora19, Ch. 7]
The avoidance of data races, which occur when data are set to either correct or incorrect values, depending upon the order in which multiple threads access and modify the data. Watch the following LinkedIn Learning video about thread safety: Thread safety from IoT Foundations: Operating Systems Fundamentals by Ryan Hu Rust is an example of a type-safe language that is also thread-safe. References
| ||||||||||||||||||||

Satellite frequency bands | ||||||
|---|---|---|---|---|---|---|
Fig. 1 depicts the usage of different frequency bands. IEEE Standard 512 [IEE20] defines the letters designating the frequency bands. According to ESA, the main satellite frequency bands range from L to Ka; see also the same link for discussion of different usage of the frequency bands.  References
| ||||||
Scan flip-flop and scan chain | ||||||||
|---|---|---|---|---|---|---|---|---|
The increasing usage of cutting-edge technologies in safety-critical applications leads to strict requirements on the detection of defects both at the end of manufacturing and in the field [VDSDN+19]. This gives birth to the design-for-testability (DFT) paradigm, which necessitates additional test circuits to be implemented on a system to 1️⃣ provide access to internal circuit elements, and thereby 2️⃣ provide enhanced controllability and observability of these elements [BT19, Sec. 4.7.1]. Scan is the most popular DFT technique [BT19, Sec. 3.7.2].
A scan chain is a chain of SFFs [BT19, Sec. 3.7.2.2]; see Fig. 2.  When Test Enable (TE) is high, the scan chain works in test/shift mode [BT19, Sec. 3.7.2.2; VDSDN+19, p. 95].
Multiple scan chains are often used to reduce the time to load and observe. The integrity of a scan chain should be tested prior to application of a scan test sequence. For more information, see the attachment. References
| ||||||||

Security definitions/notions for encryption | |||
|---|---|---|---|
See 👇 attachment.
| |||
Side-channel attacks | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
There is a bewildering array of side-channel attacks (see Definition 1). Definition 1: Side-channel attack [GGF17]
An attack enabled by leakage of information through timing, power consumption, electromagnetic, acoustic and other emissions from a physical system. It is not an understatement saying that the diversity of side-channel attacks is only limited by the creativity of humankind. A classic side-channel attack is differential power analysis (🖱 click for in-depth discussion). Meltdown and Spectre are high-profile side-channel attacks of recent years that exploit the hardware weakness CWE-1037. Below, we cover two recent attacks that are not as “classic” or “high-profile” but no less interesting. Example 1
In cybersecurity, the term “air gap” refers to an interface between two systems at which (a) they are not connected physically and (b) any logical connection is not automated (i.e., data is transferred through the interface only manually, under human control) [Shi07].
Just like physical insulation can be overcome, so can cyber insulation be. There is a group of researchers at the Ben-Gurion University of the Negev, including Mordechai Guri in the video below, that specialise in side-channel attacks, especially attacks that overcome air gaps. Watch Mordechai Guri’s Black Hat 2018 talk about “air-gap jumpers”:
Among the air-gap side-channel attacks investigated so far are PowerHammer [GZBE20], named after the infamous rowhammer attack.
How PowerHammer works in a nutshell:
 
Example 2
Quantum key distribution (QKD) is a method for generating and distributing symmetric cryptographic keys with information-theoretic security based on quantum information theory [ETS18]. The earliest QKD protocol is due to Bennett and Brassad [BB84] and is called BB84, named after the authors and the year it was proposed. BB84 encodes a classic bit in the polarisation state of a photon, which is a discrete variable, hence BB84 is an example of a discrete-variable quantum key distribution (DV-QKD) scheme. In a typical implementation of BB84, Bob uses single-photon detectors (see sample commercial products from ID Quantique SA) to receive photons from Alice, but this single-photon detector can be an Archilles’ heel of the DV-QKD system, as Durak et al. [DJK22] have shown. Among the most commonly used single-photon detectors are avalanche photodiodes (APDs), which are photodiodes with internal gain produced by the application of a reverse voltage.
Fig. 6(b) and Fig. 7 show an experimental setup an attacker can use to gather FIR data, and train a neural network for classifying received RF emission into four polarisation states. 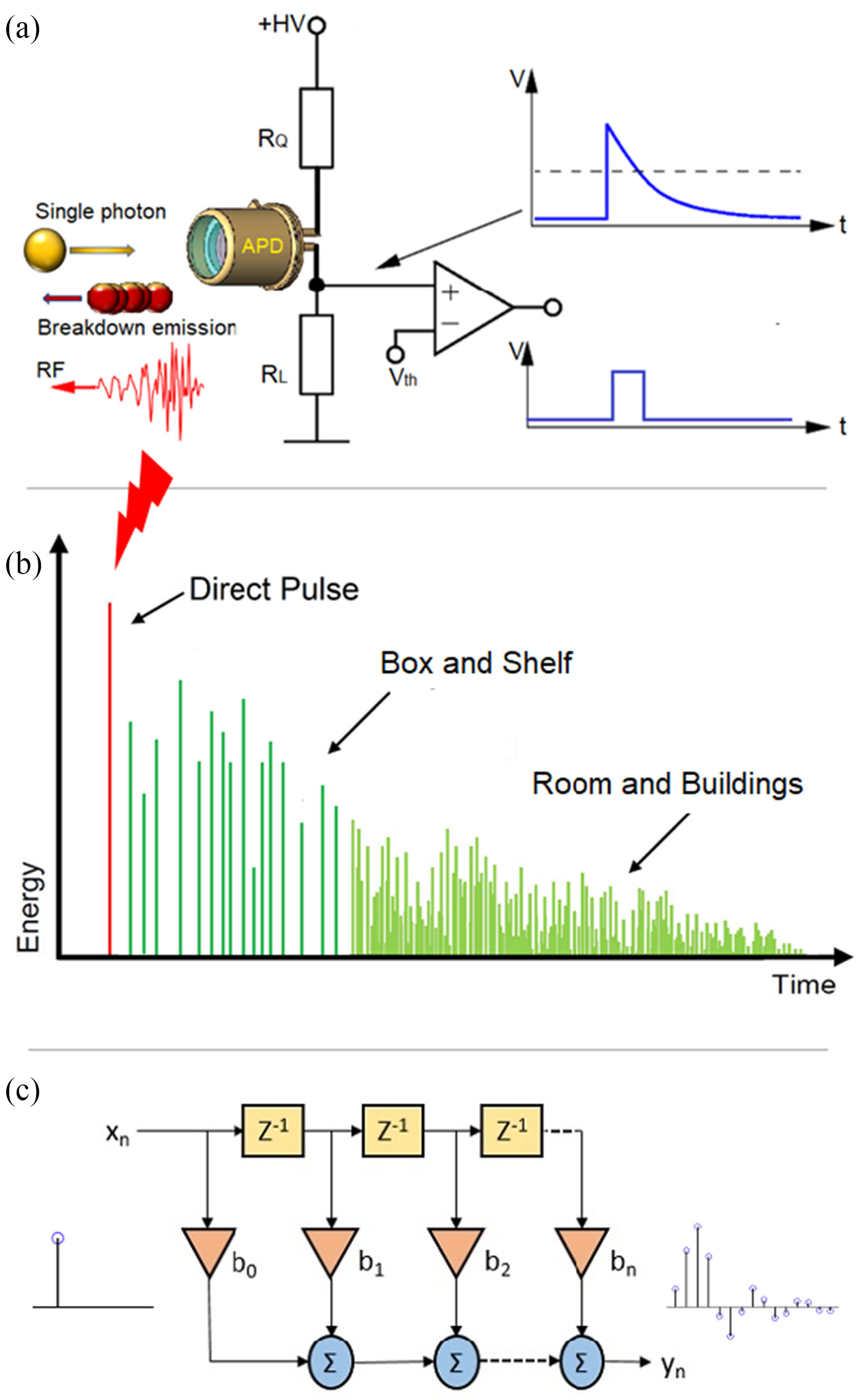 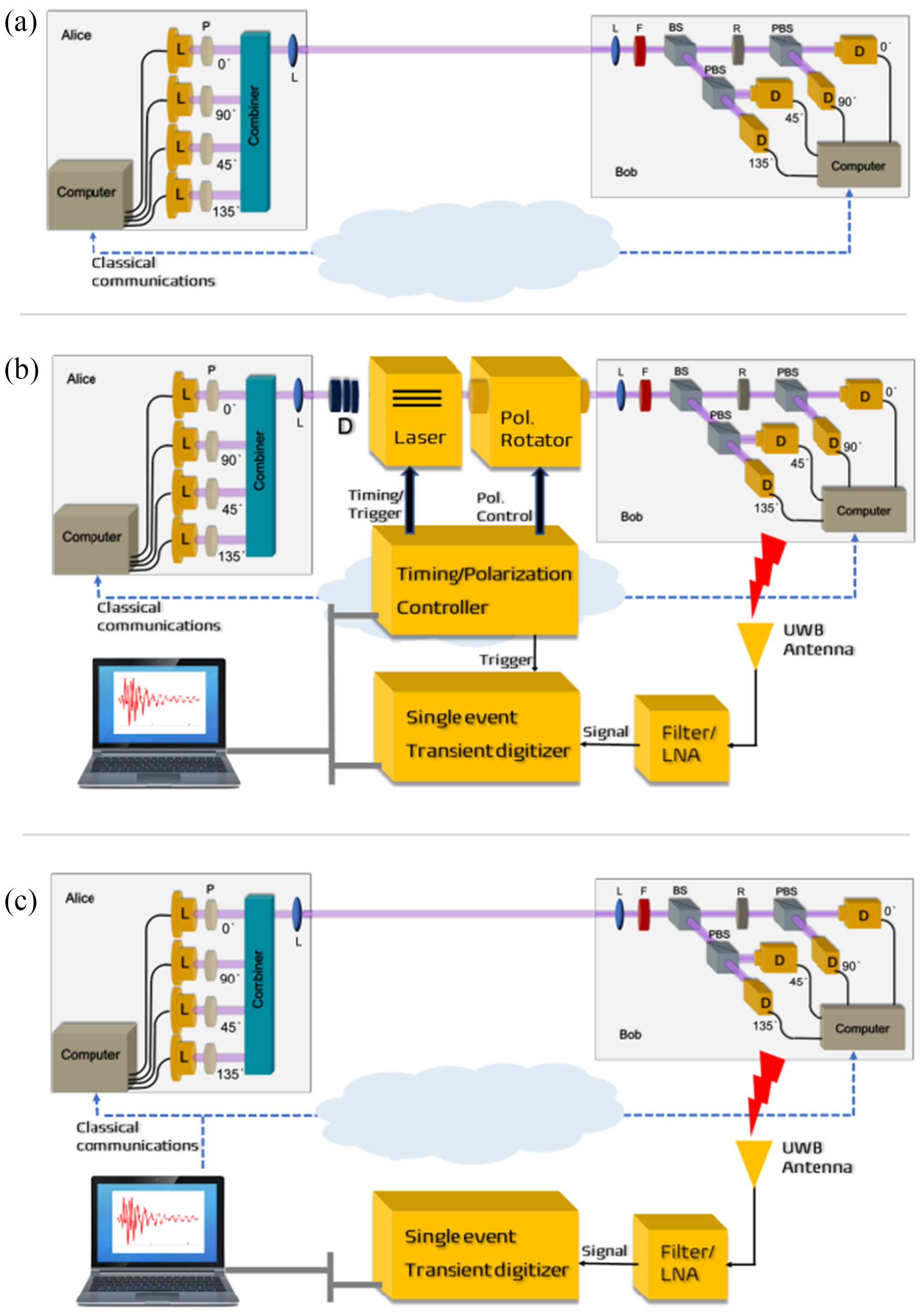  The neural network in Fig. 8 takes a time-domain sample of 256 data points, and can be trained to classify a test sample into one of four polarisation states at high accuracy. 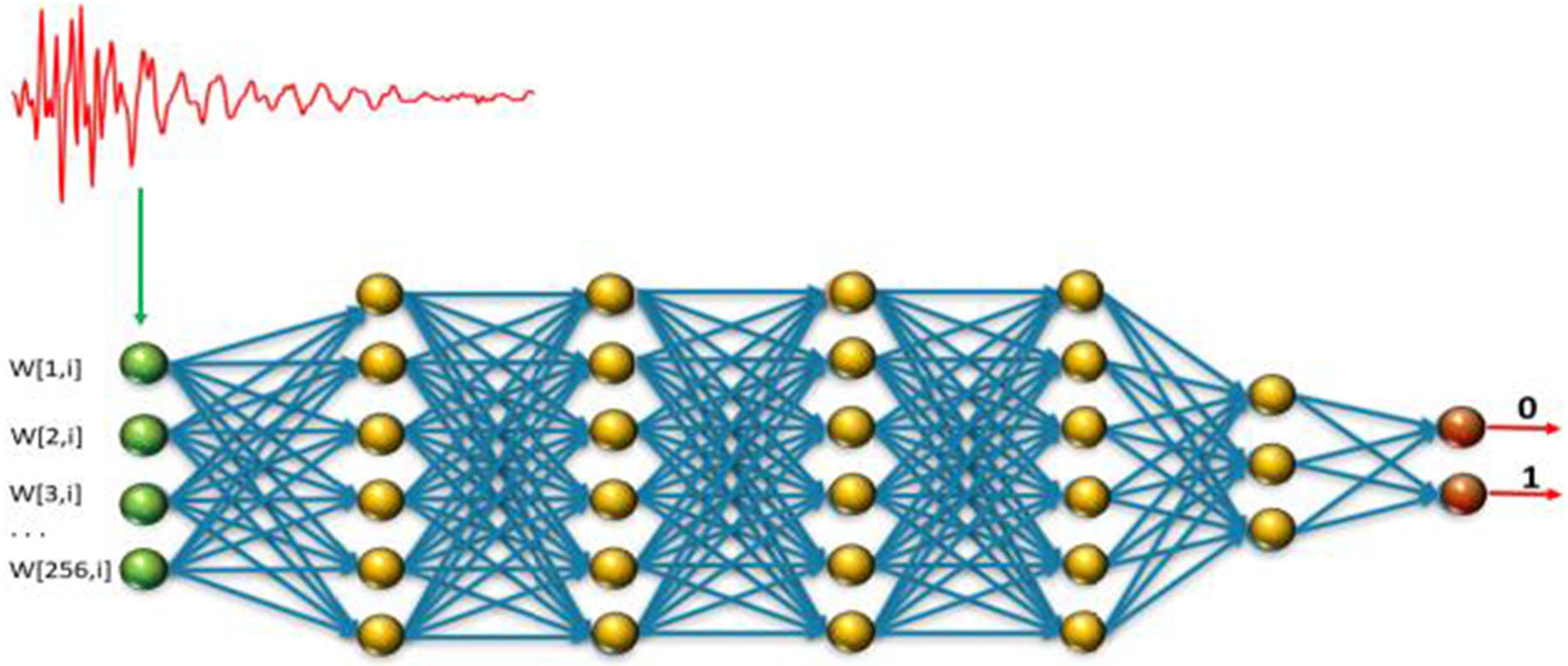 Durak et al.’s [DJK22] results demonstrate feasibility of “cloning” Bob’s qubits using an RF side channel. CountermeasuresThe countermeasures for CWE-1300 apply. References
| ||||||||||||||




Solar System Internetwork (SSI) | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
The discussion below provides some historical context, an overview and a description of the network protocol stack of the Solar System Internetwork (SSI). HistoryIn 1999, the Interagency Operations Advisory Group (IOAG) was established to achieve cross support across the international space community and to expand the enabling levels of space communications and navigation interoperability [CCS14, Foreword]. In 2007, the IOAG chartered a Space Internetworking Strategy Group (SISG) to reach international consensus on a recommended approach for transitioning the participating agencies towards a future network-centric era of space mission operations [CCS14, Foreword]. In 2008, the SISG released a preliminary report on their operations concept for a Solar System Internetwork (SSI) [CCS14, Foreword]; see the 2011 conference version of the report [EDB11]. In 2010, the IOAG finalised the SSI Operations Concept and asked the Consultative Committee for Space Data Systems (CCSDS) to create the SSI architectural definition [CCS14, Foreword]. In 2014, the CCSDS Space Internetworking Services - Delay-Tolerant Networking (SIS-DTN) working group released the official informational report [CCS14]. The SSI architecture is based on international standards and voluntary agreements [CCS14, Executive Summary]. Participation in the SSI is expected to be incremental, and furthermore, the SSI specification and technologies are still evolving. In fact, the Interplanetary Networking Special Interest Group (IPNSIG), a chapter of the Internet Society, has the vision to develop a secure and robust Solar System Internet, by extending networking to space, from the historical point-to-point, “bent pipe” communication architecture to a store-and-forward, packet-switched design, interconnecting any number of terrestrial and space-borne nodes [KCB+21]. OverviewThe fundamental objective of the SSI is to provide automated and internetworked data communication services for space ventures (at least across the solar system) [CCS14, Executive Summary; EDB11, Sec. 2]. The emphasis on automation arises from the need to support communication among the various participants operating in space ventures without requiring a detailed understanding of space communication operations [CCS14, Executive Summary]. Examples of participants include [CCS14, Sec. 2.1]:
The SSI interconnects multiple networks built on two types of networking architectures, namely 1️⃣ the Internet architecture and 2️⃣ the DTN architecture. Fig. 1 depicts a communication scenario that the SSI architecture is designed to support.  In Fig. 1,
To accommodate the multi-agency, multi-mission scenario in Fig. 1, the SSI architecture specifies three stages of functionality:
Protocol stackThe SSI protocol stack is a combination of the Internet Protocol (IP) stack and the Delay-Tolerant Network (DTN) protocol stack, as shown in Fig. 2. Going top-down along the DTN “facet” (CCSDS term) [CCS14, Sec. C3],
 Fig. 3: A sample instantiation of the CCSDS protocol stack [CCS20d, Figure 2-1], where CLA = convergence layer adapter. 
 Fig. 5: DTN protocol building blocks in an end-to-end ABCBA view [CCS18, Figure 3-3]. In CCSDS terminology [CCS15b, Sec. 1.6.1], an ABCBA view/configuration refers to a multi-hop space communications configuration involving 1️⃣ multiple space and ground elements and 2️⃣ multiple direct earth-space and space-space links. ABCBA configurations nominally include elements from three or more agencies.  
References
| ||||||||||||||||||||||||

Solar System Internetwork (SSI) Stage 1 Mission Functionality | |||
|---|---|---|---|
This continues from Solar System Internetwork (SSI). The Stage 1 Mission Functionality of the Solar System Internetwork (SSI) is the automation of basic communication processes between vehicles and Mission Operations Centers (MOCs) that might be performed for a single space flight mission, including [CCS14, Sec. 3]:
Fig. 1 depicts a sample communication scenario between two SSI nodes: one onboard the spacecraft and another at the spacecraft MOC.
 The network configuration in Fig. 1 can be extended by setting up a separate SSI node for use by the instrument MOC, enabling the instrument MOC to operate on native instrument data flows securely routed through the node at the spacecraft MOC. Prerequisites and protocolsTo be part of the SSI, each node must be configured to run the Bundle Protocol (BP), i.e., a Bundle Protocol Agent (BPA) must be deployed at each node. For each node on the Earth surface, a Convergence-Layer Adapter (CLA) must be deployed underneath BP, enabling the node to communicate with other Earth-bound nodes via the Internet. For interoperation with the Internet, the CLA can use the Transmission Control Protocol (TCP) and User Datagram Protocol (UDP), or potentially the Licklider Transmission Protocol (LTP) running on top of UDP/Internet Protocol (IP). References | |||
Space Attack Research and Tactic Analysis (SPARTA) | ||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
SPARTA: Space Attack Research and Tactic AnalysisBy The Aerospace Corporation  The Aerospace Corporation created the Space Attack Research and Tactic Analysis (SPARTA) cybersecurity matrix
The SPARTA matrix is a specialisation of the MITRE ATT&CK matrix for defining and categorising commonly identified activities that contribute to spacecraft compromises. The nine SPARTA tactics shown in the top row of Fig. 1 are a subset of the tactics in MITRE ATT&CK.  Under each SPARTA tactic in Fig. 1, each of the main techniques accompanied by a double vertical sign, namely ⏸, can be divided into sub-techniques. For example, under tactic “Reconnaissance” (ST0001), the technique “Gather Spacecraft Design Information” (REC-0001) can be divided into 1️⃣ Software (REC-0001.01), 2️⃣ Firmware (REC-0001.02), 3️⃣ Cryptographic Algorithms (REC-0001.03), 4️⃣ Data Bus (REC-0001.04), 5️⃣ Thermal Control System (REC-0001.05), 6️⃣ Manoeuvre and Control (REC-0001.06), 7️⃣ Payload (REC-0001.07), 8️⃣ Power (REC-0001.08), and 9️⃣ Fault Management (REC-0001.09). Example 1: Payload
The South Australian 6U CubeSat Kanyini has two payloads: 1️⃣ a hyperspectral imager called HyperScout 2 for earth observation, and 2️⃣ an Internet-of-Things communications module. Example 2: Applying SPARTA to modelling a recent cyber attack
Watch a quick overview of the attack called PCspooF: A mixed-criticality system (MCS) is an embedded computing platform in which application functions of different criticalities share computation and/or communication resources [EDN16]. A mixed time-criticality system is an MCS where the criticality is messaging timeliness. Time-Triggered Ethernet (TTEthernet), as standardised in SAE AS6802, defines algorithms for clock synchronisation, clique detection, startup, and restart for switches and end systems to achieve fault-tolerant synchronisation in an Ethernet-based (IEEE 802.3) mixed time-criticality system. TTEthernet is used in avionics, industrial control systems (including those for power systems) and automotive systems [LPDK23], so any security vulnerability in TTEthernet would have wide-reaching consequences.
How TTEthernet works [LPDK23] A TTEthernet network contains two types of devices: switches and end systems. Fault-tolerance is enabled by network redundancy, and each redundant network is called a plane; Fig. 2 shows an example of a system using two planes. Time-triggered (TT) design = All TTEthernet devices are tightly synchronised and the behaviour of the network is determined by a global schedule made offline and loaded onto each TTEthernet device before deployment. 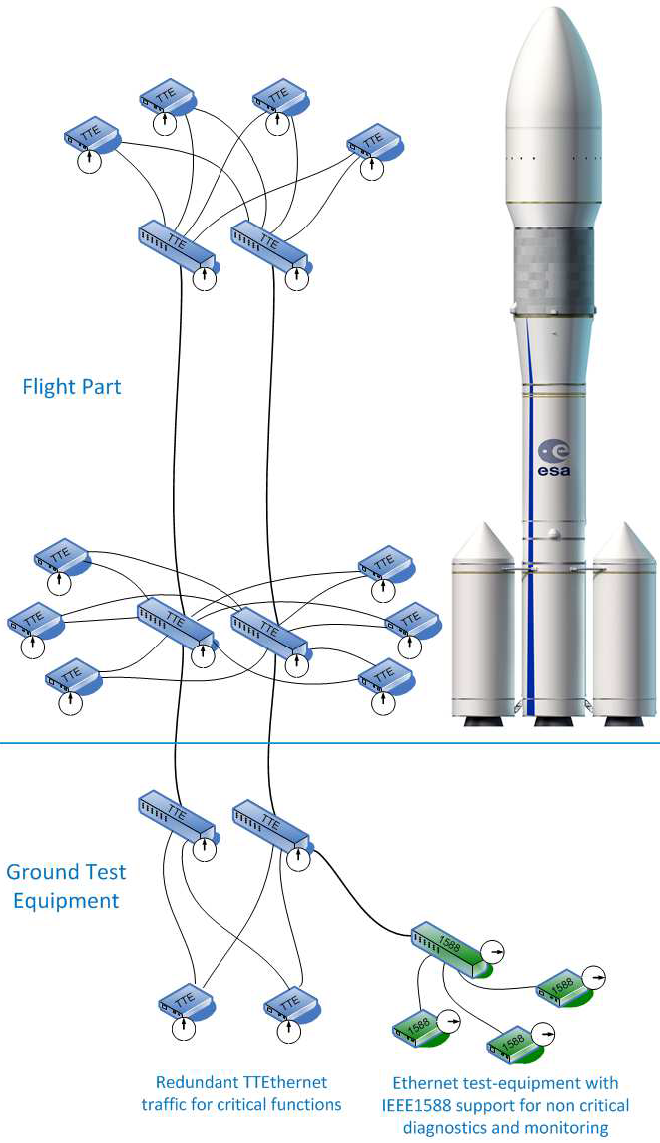  The global schedule specifies when TT frames are forwarded and expected to arrive. The latency and jitter of TT traffic can be reduced to below 13 μs and 1 μs respectively [Fid15, slide 12]. TTEthernet also carries best-effort (BE, i.e., regular) Ethernet traffic and rate-constrained Avionics Full Duplex Switched Ethernet (AFDX, as standardised in ARINC Specification 664 P7-1) traffic; see Fig. 3. TTEthernet switches forward BE traffic around the pre-scheduled TT traffic when bandwidth permits. Mechanisms exist to isolate TT traffic from BE traffic, e.g.,
Central to TTEthernet is a synchronisation protocol, in which a device can participate as 1️⃣ a sync master, 2️⃣ a compression master, or 3️⃣ a sync client.
Devices exchange protocol control frames (PCFs) every integration cycle.
Receiving certain PCFs from a compression master can cause sync masters and clients to lose synchronisation.
Attacker/threat model for PCspooF The PCspooF attack is feasible provided:
  The PCspooF attack PCspooF is a cyber-physical attack that attempts to disrupt the TTEthernet synchronisation protocol by spoofing PCFs, and thereby inflict denial of service on its victim. The attack happens in two stages:
Applying SPARTA Using the language of SPARTA, these attack stages can be identified [The22]: 1️⃣ Reconnaissance, 2️⃣ Resource Development, 3️⃣ Initial Access, 4️⃣ Execution, 5️⃣ Lateral Movement, 6️⃣ Impact Table 1 and Table 2 map these attack stages to the attack steps in PCspooF.
References
| ||||||||||||||||||||||||||





Space Packet Protocol (SPP) | ||||||||
|---|---|---|---|---|---|---|---|---|
IntroductionIn many space applications, it is desirable to have a single, common application-layer data structure for the creation, storage, and transport of variable-length application-layer data. These data is expected to be 1️⃣ exchanged and stored on board, 2️⃣ transferred over one or more space data links, and 3️⃣ used within ground systems. It is often necessary to identify the 1️⃣ type, 2️⃣ source, and/or 3️⃣ destination of these data. The preceding needs motivate the definition of the Space Packet Protocol (SPP). The SPP is designed as a self-delimited carrier of a data unit — called a Space Packet — that contains an application process identifier (APID) used to identify the data contents, data source, and/or data user within a given enterprise [CCS20d, Sec. 2.1.1]. Fig. 1 shows where the SPP sits in the CCSDS protocol stack. Fig. 2 shows a communication scenario between a spacecraft and a ground terminal, where the SPP plays an important role. Fig. 1: The SPP sits above the data link layer and below the upper layers in the CCSDS protocol stack [CCS20d, Figure 2-1], where CLA = convergence layer adapter.  Fig. 2: A sample communication scenario [CCS20a, Figure 9-12], featuring mission operations (MO) applications residing in the spacecraft’s onboard computer (OBC). All OBC apps are under the control of a real-time operating system (RTOS); with the striped blocks running in hard real time. Science operations (SO) functions are executed through Message Transfer Service, File and Packet Store Services, etc. The yellow blocks represent the spacecraft onboard interface services (SOIS), and the SPP is one of these services. Between the SPP and the MO applications sits the Message Abstraction Layer (MAL) [CCS13a], an important component of CCSDS’s Missions Operations Framework. For applications on separate onboard computers, communications pass through the whole stack and use the physical subnetwork to communicate. For applications on the same computer, communications pass through the stack to a local loopback function in the software bus.  APIDAPIDs are unique in a single naming domain [CCS20d, Sec. 2.1.3] An APID naming domain usually corresponds to a spacecraft, or an element of a constellation of space vehicles. Every space project allocates the APIDs to be used in a naming domain. More precisely, the space project assigns APIDs to managed data paths within a naming domain. Open-source implementationsThe following open-source implementations are known at the time of writing:
References
| ||||||||
Spectre attacks | ||||
|---|---|---|---|---|
The Spectre attacks exploit the weakness CWE-1037 “Processor Optimization Removal or Modification of Security-critical Code”. Modern processors use branch prediction and speculative execution to maximise performance, but the implementations of these optimisations in many processors were found to have broken a range of software security mechanisms, including operating system process separation, containerisation, just-in-time (JIT) compilation, and countermeasures to cache timing and side-channel attacks [KHF+20]. Watch the presentation given by one of the discoverers of Spectre attacks at the 40th IEEE Symposim on Security and Privacy: More information on the Meltdown and Spectre website. References
| ||||

Spread spectrum and frequency hopping | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Frequency hopping is one of two main spread spectrum techniques. Spread spectrumA spread-spectrum signal is a low-probability-of-intercept (LPI) signal with extra modulation that expands the signal bandwidth greatly beyond what is required by the underlying channel code (e.g., low-density parity-check codes) and modulation [Tor18]. High-level idea [Ada01, pp. 123-124]:
 Spread-spectrum communication systems are useful for 1️⃣ suppressing interference, 2️⃣ making secure communications difficult to detect and process, 3️⃣ accommodating fading and multipath channels, and 4️⃣ providing multiple-access capability. Spread-spectrum signals cause relatively minor interference to other systems operating in the same spectral band. Two dominant spread-spectrum systems: 1️⃣ direct-sequence and 2️⃣ frequency-hopping. Frequency-hopping spread spectrum (FHSS)Intuition: If using one communication channel allows our adversary to sense our channel and subsequently jam it, then it would make sense for us to hop 🐇 from one channel to channel in such a way that it is hard to detect. The sequence of carrier frequencies is called the frequency-hopping pattern; see Fig. 2. The set of possible carrier frequencies is called the hopset. Each of the frequency channel is defined as a spectral region that 1️⃣ includes a single carrier frequency of the hopset as its centre frequency and 2️⃣ has a bandwidth large enough to include most of the power in a single pulse. The rate at which the carrier frequency changes is the hop rate. The time interval between hops is the hop interval, and its length is called hop duration ( in Fig. 2).  The frequency band within which hopping occurs is the hopping band, and its bandwidth is called hopping bandwidth ( in Fig. 2). Figs. 3-4 show the general form of a frequency-hopping transmitter and the general form of a frequency-hopping (FH) receiver respectively.
On the transmitter end in Fig. 3, the pattern generator generates a set of pattern-control bits at the hop rate. The frequency synthesiser synthesises an FH pattern based on the pattern-control bits. To ensure that an FH pattern is difficult to reproduce or dehop by an adversary, the pattern should be 1️⃣ pseudorandom with a large period and 2️⃣ as uniformly distributed over the frequency channels as possible. The data-modulated signal is mixed with the FH pattern to produce the FH signal. On the receiver end in Fig. 4, the same FH pattern on the transmitter end is replicated here in synchrony. The mixing operation, called dehopping, removes the FH pattern from the received signal. The bandpass filter removes the double-frequency components and produces the data-modulated dehopped signal. Example 1
An example of commercial transceivers that support FHSS is Murata’s DNT24 series of 2.4 GHz FHSS wireless transceivers [Wil14]. These transceivers support the establishment of a store-and-forward (i.e., delay-tolerant) network (see Fig. 5), which consists of a base node connected to router nodes, which are in turn connected to remote nodes.  For base nodes, the hop duration can range from 8 ms to 100 ms, and has the default value of 20 ms [Wil14, Sec. 7.4]. Other nodes synchronise their hop duration with the base. Pros Compared to direct-sequence spread spectrum (DSSS), FHSS 1️⃣ offers more resilience to interference, and is thus better suited for co-located systems; 2️⃣ enables higher channel utilisation [Wil14]. DSSS also requires more circuitry (higher cost) to implement, is more energy-consuming and more sensitive to environmental effects [Law05, Sec. 2.3.2]. Cons However, FHSS systems require an initial acquisition period during which the receiver must lock on to the moving carrier of the transmitter before any data can be sent, which typically takes several seconds [Wil14]. References
| ||||||||||||||







Stream ciphers | |||
|---|---|---|---|
See 👇 attachment. | |||
Systems Security Engineering | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
NIST provides guidelines on engineering trustworthy (see Definition 1) and cyber-resilient (see Definition 2) systems through NIST SP 800-160 volumes 1 and 2 [RWM22, RPG+21], to be used in conjunction with
Definition 1: Trustworthy [RWM22, p. 1]
Worthy of being trusted to fulfill whatever critical requirements may be needed for a particular component, subsystem, system, network, application, mission, enterprise or other entity. Definition 2: Cyber-resilient [RPG+21, p. 1]
Able to anticipate, withstand, recover from, and adapt to adverse conditions, including stresses, attacks, and compromises on systems that use or are enabled by cyber resources. 📝 A cyber resource is an information resource which creates, stores, processes, manages, transmits, or disposes of information in electronic form and that can be accessed via a network or using networking methods; for example, a file or database. A primary objective of NIST SP 800-160 volume 1 is to provide a basis for establishing a discipline for systems security engineering as part of systems engineering in terms of its principles, concepts, activities and tasks.
 A primary objective of NIST SP 800-160 volume 2 is to provide guidance on how to apply cyber resilience concepts, constructs and engineering practices to systems security engineering and risk management for systems (e.g., enterprise IT, industrial control systems, Internet of Things) and organisations. References
| ||||||||||||
T |
|---|
Transport Layer Security | |||
|---|---|---|---|
TODO | |||
Trusted autonomy | ||||
|---|---|---|---|---|
Trusted Autonomy (TA) is a field of research that focuses on understanding and designing the interaction space between two entities each of which exhibits a level of autonomy [APM+16]. References
| ||||
Type checking | ||||
|---|---|---|---|---|
Type checking checks that program statements are well-formed with respect to a typing logic [vJ11, p. 1255]. For example, integers can be added and functions can be called, but integers cannot be called and functions cannot be added. Type checking can be used to ensure programs are type-safe, meaning that at every step of the execution, all values have well-defined and appropriate types, and that there is a valid next step of execution. References
| ||||
U |
|---|
Unified Threat Management | ||
|---|---|---|
See attachment. | ||
Universally composable security | ||||
|---|---|---|---|---|
First proposed by Canetti [Can01], the paradigm of universally composable security guarantees security even when a secure protocol is composed with an arbitrary set of protocols, or more generally when the protocol is used as a component of an arbitrary system.
References
| ||||
USRP SDRs | ||||
|---|---|---|---|---|
Work in progress
Ettus’s wiki for B210. Ettus’ wiki for X300/X310 Setting up UHD through Anaconda and GNU Radio. Verifying operation. PySDR: A Guide to SDR and DSP using Python, set up UHD following Ch. 6 (original instructions). Note highest Python version supported is 3.9. Use conda to save trouble. Stuck at /sbin/ldconfig.real: Can't link /usr/lib/wsl/lib/libnvoptix_loader.so.1 to libnvoptix.so.1 /sbin/ldconfig.real: /usr/lib/wsl/lib/libcuda.so.1 is not a symbolic link >>> x310 = uhd.usrp.MultiUSRP("type=x300")
[INFO] [X300] X300 initialization sequence...
Traceback (most recent call last):
File "stdin", line 1, in module
File "C:\Users\lawyw\Miniconda3\envs\gnuradio\Lib\site-packages\uhd\usrp\multi_usrp.py", line 30, in __init__
super(MultiUSRP, self).__init__(args)
RuntimeError: RuntimeError: Expected FPGA compatibility number 39.0, but got 13.0:
The FPGA image on your device is not compatible with this host code build.
Download the appropriate FPGA images for this version of UHD.
As an Administrator, please run:
"C:\Users\lawyw\Miniconda3\envs\gnuradio\Library\bin\uhd\utils\uhd_images_downloader.py"
Then burn a new image to the on-board flash storage of your
USRP X3xx device using the image loader utility. Use this command:
"C:\Users\lawyw\Miniconda3\envs\gnuradio\Library\bin\uhd_image_loader" --args="type=x300,addr=192.168.10.2"
For more information, refer to the UHD manual:
http://files.ettus.com/manual/page_usrp_x3x0.html#x3x0_flash
References
| ||||